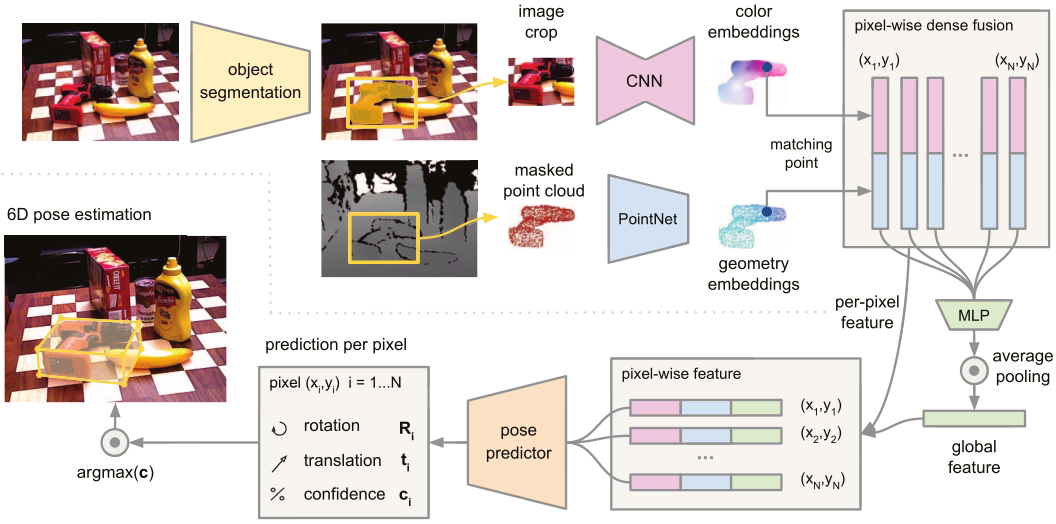
抓取姿态估计算法调研
Hybrid Physical Metric For 6-DoF Grasp Pose Detection
标题:用于6D抓取检测的混合物理度量
作者团队:清华大学(王生进)
期刊会议:ICRA
时间:2022
代码:https://github.com/luyh20/FGC-GraspNet
一、目标问题
单个物理指标会导致离散的抓取置信度分数,在百万抓取数据训练时会导致预测结果不准确。
本文定义了一种新的度量方式,基于力封闭度量、物体平面度、重力和碰撞测量。
本文设计了平面重力碰撞FGC-GraspNet,适用于多任务多分辨率学习体系。
二、混合物理度量
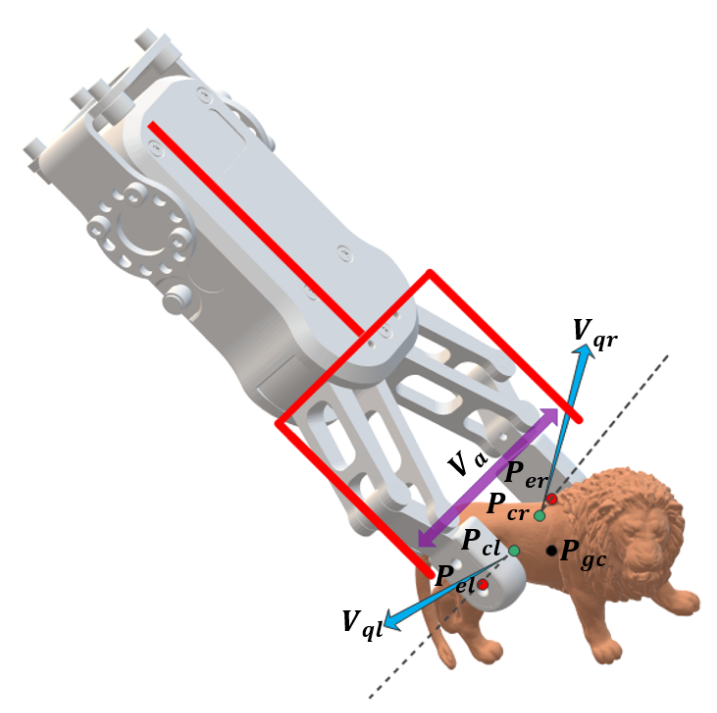
(1)平面度
平面度越高的抓的越稳。利用点的局部法向量的相似性计算平坦度得分。
(2)重心度量
夹持力更接近物体重心的更稳定。计算物体重心到两个接触点的连线的距离作为重力得分。
(3)碰撞扰动度量
当夹爪接近物体时容易发生碰撞,因此取夹爪两个最大行程端点与物体接触点的欧氏距离最小值作为碰撞扰动得分。
(4)混合物理度量
混合物理度量是上面度量的加权组合。
三、 FGC-GraspNet
通过最远点采样FPS得到20000x3对点云输入,网络由PointNet++,FA分支、RD分支组成。
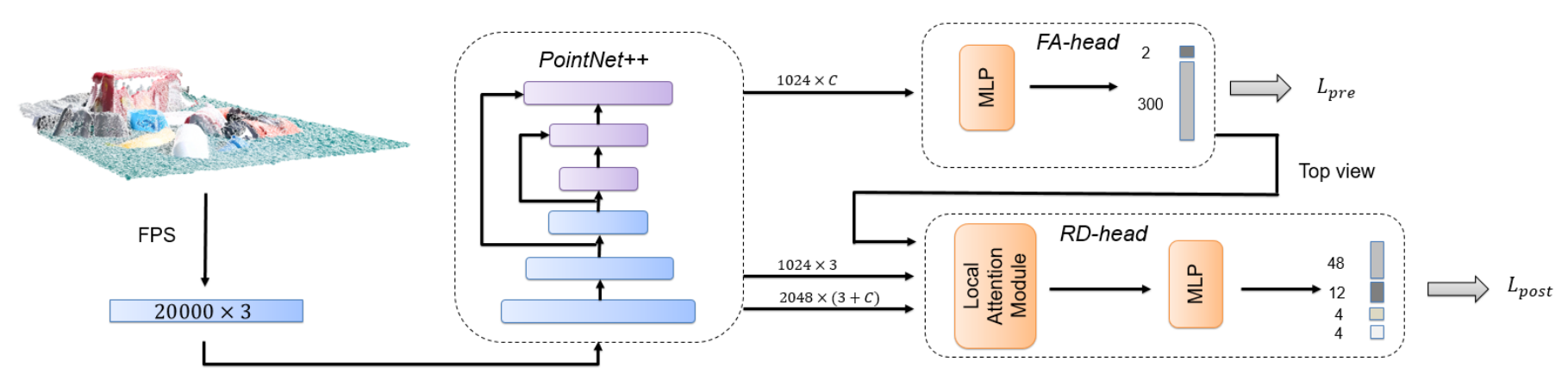
- PointNEt++用于提取点特征
- 低分辨率的特征进入FA分支进行前景分割和逐点逼近方向得分回归
- 高分辨率的特征用于RD旋转分支。
四、思考
将混合物理度量纳入LOSS的计算过程确实有意义。而且具有一定的复用性,其它算法也可借鉴此设计。
Volumetric Grasping Network: Real-time 6 DOF Grasp Detection in Clutter
标题:基于体素的抓取网络:杂乱场景中实时6D抓取检测
作者团队:ETH Zurich(苏黎世联邦理工学院)
期刊会议:CoRL2020
时间:2020
代码:https://github.com/ethz-asl/vgn
一、目标问题
本文提出了一种网络从深度相机中获得场景信息,预测6D抓取的网络。
二、论文方法
(1)网络架构
由滤波器、卷积层组成的感知模块将输入体素映射为特征图,然后进行卷积、上采样操作,最后是三个独立的分支用于预测抓取质量、旋转和夹爪宽度。
(2)抓取检测
使用一些方法去除不可能的抓取姿势,然后应用非极大抑制来获得候选的抓取列表。
三、思考
非常基础的方法,已经有人在此基础上进行了扩展并发表了顶会。
Efficient Learning of Goal-Oriented Push-Grasping Synergy in Clutter
标题:杂乱场景中面向目标的的推/抓协同有效学习
作者团队:浙江大学(熊蓉)
期刊会议:RAL
时间:2021
代码:https://github.com/xukechun/Efficient_goal-oriented_push-grasping_synergy
一、目标问题
在混乱场景中抓取物体时,有时需要一些预抓取动作,例如推动。使机械臂能够分离目标对象并稳定的实现抓取。
二、方法

环境准备:固定的RGBD相机拍摄工作空间,将RGBD投影到重力方向,使用颜色高度图和深度高度图表示每个状态。
(1)有目标的抓取训练
训练一个有目标条件下的抓取网络,当有足够的训练之后,成功抓取的Q值稳定。
(2)有目标的推动训练
训练一个有目标条件下的推动网络,推动的奖励函数是基于抓取网络反向训练设计的。
(3)交替训练
利用交替训练来解决物体分布不匹配的问题,进一步提高混乱环境中抓取策略性能。
三、思考
推物体再抓取物体相当于一个两阶段方法,可以不用在底层进行训练,而是在高层的规划决策层来进行判断,发布任务是推物体还是抓物体。
TransGrasp: Grasp Pose Estimation ofaCategory ofObjects byTransferring Grasps fromOnlyOne Labeled Instance
标题:杂乱场景中面向目标的的推/抓协同有效学习
作者团队:大连理工大学(孙怡)
期刊会议:ECCV
时间:2022
代码:https://github.com/yanjh97/TransGrasp
一、目标问题
现有大多数方法需要大量的抓取数据来训练,为了解决这个问题,本文实现只标记一个对象预测一类对象的抓取姿态。
二、方法
(1)学习类别的对应关系
- Shape Encoder和DIFDecoder组成神经网络,训练得到对象变形到模板的密集对应关系
(2)抓取姿态估计
- 点云首先从相机坐标系转换到对象坐标系
- 生成对象实例的变形到模板
- 将带有抓取注释的模型输入到DeformNet中获得模型的变形
- 由两者的共同模板见你对应关系,通过对准物体表面上的抓握点来引导抓握姿势的变换
- 通过refine模块进行优化
- 将优化后的抓握知识转换为相机坐标进行抓取
三、思考
这种算法只能实现与模板形状相似的物体进行抓取,而且每个类别要先手工标记1000个抓握姿势。
Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes
标题:ContactGraspNet:在杂乱场景中高效生成6-DoF抓取
作者团队:NVIDIA
期刊会议:ICRA
时间:2021
代码:https://github.com/NVlabs/contact_graspnet
1 目标问题
提出了一种端到端的网络,从图像的深度数据中生成6D抓取分布。
2 方法
使用原始的深度图,以及(可选使用对象掩码),生成6D抓取建议以及抓取宽度。
(1)抓取表示方法
可以发现,大多是可以预测的两手指抓取,在抓取前至少可以看到两个接触点的一个。因此可以将抓取问题简化为估计平行板抓取器的3D抓取旋转和抓取宽度。
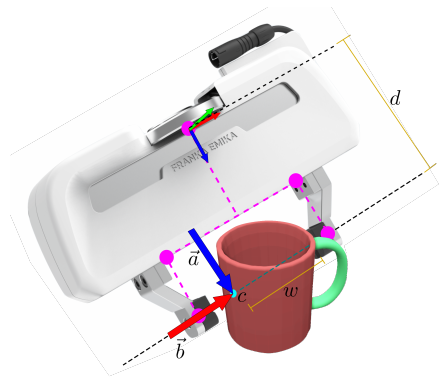
其中a是接近向量,b是抓取基线向量,d是从抓取基线到抓取基座的距离。使用这种表示方法可以加速学习过程,提高预测精度,且没有歧义和间断区域。
(2)数据生成
使用了ACRONYM数据集。在场景中以随机稳定的姿态放置具有密集抓取注释的对象网格。其中会导致夹爪与模型碰撞的抓取姿态将被删除。
(3)网络
使用PointNet++中提出的集合概要和特征传播层来构建非对称的U形网络。
网络有四个检测头,每个检测头包括两个1D卷积层,每个点输出s∈R,z1∈R3,z2∈R3、o∈R10,从中我们形成了我们的抓取表示。
将抓取的宽度划分为10个等距的抓取宽度,来抵消数据不平衡问题,然后选择置信度最高的抓取宽度表示。由于接近方向和基线方向是正交的,通过进行正交归一化预测,将这一性质加入到训练过程,有助于3D旋转的回归。

3 思考
在数据集中预先定义好了抓取姿态,然后进行监督训练。使用时根据深度图首先确定物体所在区域,然后利用其点云预测抓取分布。
自定义物体的数据集不易制作。
RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
标题:RGB Matters:单RGBD图像学习学习7D抓取姿态
作者团队:上海交通大学(卢策吾)
期刊会议:ICRA
时间:2021
代码:https://github.com/GouMinghao/RGB_Matters
一、目标问题
现有方法要么生成自由度很少的抓取姿态,要么只将不稳定的深度点云输入。
二、方法
(1)Angle-View Net
预测像素级的夹持器旋转配置。直接回归四元数不太现实,而且不鲁棒。可以使用下面的模型,将夹持器旋转预测作为一个分类问题进行预测。
AVN最终的输出表示为角视图热图。
(2)快速分析搜索
AVN识别了7个自由度的其中五个,但是夹持器的宽度和夹持器沿轴方向的自由度还没有确定。
本文提出了基于碰撞和空抓取检测的快速分析搜索来计算宽度和距离。
通过对从0到Wmax采样,假设抓取器靠近由深度图重建的点云的对应点。过滤掉夹持器占用的空间中存在点、抓取空间没有点的两种情况。

三、思考
本文使用了尽可能简单的思路解决抓取预测问题
将末端夹持器的旋转方向通过分类器进行回归计算。
将夹持器位置和宽度通过采样测试逐一排除得到最优解。
思路直观简单,可以尝试。
CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation
标题:CaTGrasp:从仿真中学习杂乱场景的类别级抓取
作者团队:Rutgers University(美国罗格斯大学)
期刊会议:ICRA
时间:2022
代码:https://github.com/wenbowen123/catgrasp
一、目标问题
提出了一个框架学习工业对象的抓取,不需要真实的数据或手动注释
二、方法
给定同一类别的3D模型的数据库,该方法学习
- 以对象为中心的NUNOCS表示
- hotmap:抓握过程中手-对象接触区域的任务实现成功的可能性
- 抓取姿势的编码本
(1)类别级标准NUNOCS表示
将同一个类别的不同实例对象转换到标准空间,并缩放为标准大小。
(2)稳定抓取学习
首先给定从当前实例到规范模型的9D变换,将相同的变换应用于抓取来得到抓取建议。
将生成的抓取用于训练基于PointNet构建的网络,预测抓取质量。
(3)实例分割
使用了3D U-Net,将整个场景的点云作为输入,预测每点偏移到物体中心,将偏移点聚类为实例段。
(4)仿真中生成训练数据
利用PyBullet模拟生成合成数据。
三、思考
该方法提出了一种使用仿真数据进行训练,减少人工标注的方法。抓取的方法没有太多创新,仍然需要每个类别提供多个预先的实例以及抓取姿态用于训练。
Closed-Loop Next-Best-View Planning for Target-Driven Grasping
标题:闭环次优视图规划用于目标驱动的抓取
作者团队:ETH Zurich(苏黎世联邦理工学院)
期刊会议:IROS
时间:2022
代码:https://github.com/ethz-asl/active_grasp
一、目标问题
从密集遮挡环境中抓取物体
二、方法
该方法具有以下前提条件
- 机械臂末端连接深度相机
- 相机光学中心和手抓中心已经校准
- 已知物体的部分视图和3D边界框
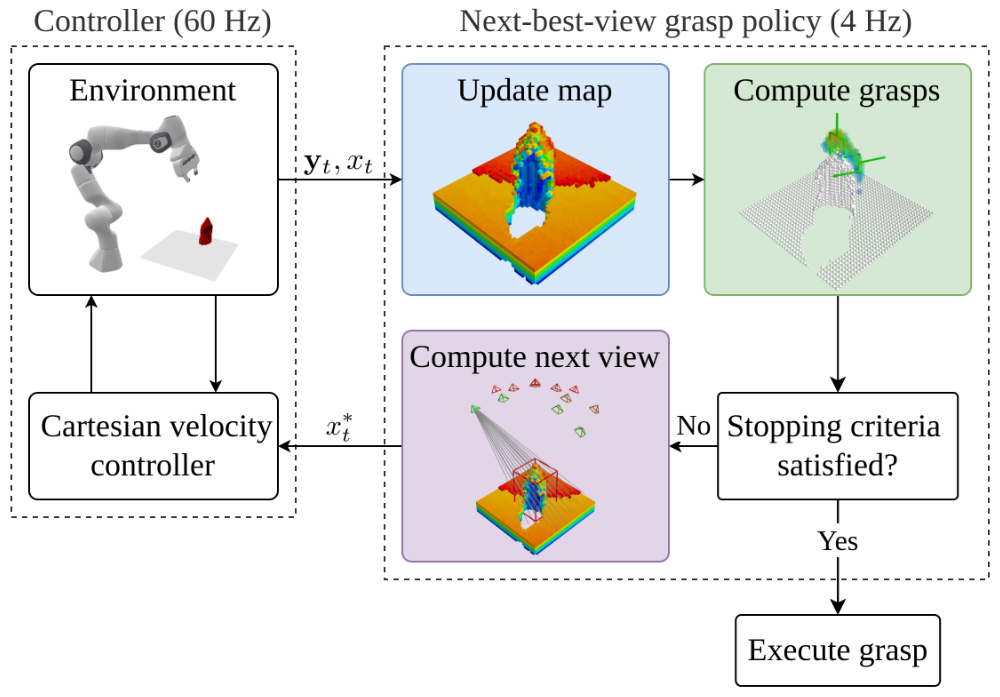
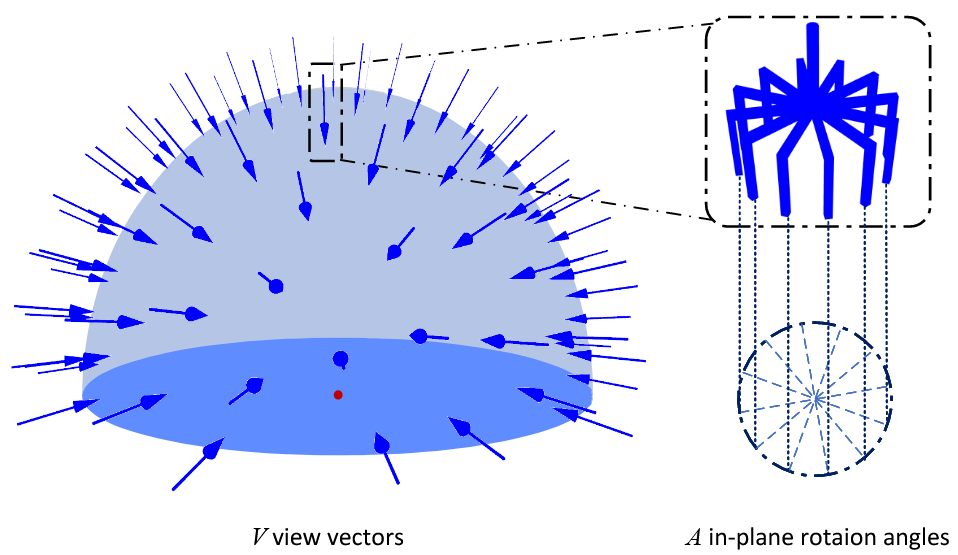
首先将点云观测yt和相机姿态xt继承,重建为体素图。计算体素的可抓取性,以及可能的抓取姿态。如果可抓取性不满足要求,就调整机械臂位置计算下一张图
(1)抓取检测
使用体积抓取网络VGN进行抓取。该网络将体素网格M映射到抓握质量分数Q、平行抓握方向R、开口宽度W。
过滤掉指尖不在目标边界框的抓取姿态、无法找到反向运动学解的抓取姿态。
(2)次优视图规划器
世界表示:使用TSDF(截断有符号距离函数)表示大小为 l 的立方体体素。
视图生成:将候选视图生成在目标边界上半球内。
信息增益:TSDF 重建的完整性对于抓取的检测和预测准确性有很大影响。因此使用了后侧体素 IG 公式的变体,对被遮挡具有负距离的体素使用光线投影来计算隐藏对象体素的数量。
- 在策略更新的最大数量中加入时间预算
- 如果抓取分数低于给定的阈值,就会停止算法,因为获取不到有用信息
- 如果VGN在几帧内保持稳定的抓取配置,就停止
三、思考
该方法是在位姿估计的基础上进行的抓取预测,可以将该方法与Gen6D结合起来,获得物体的6D抓取位姿。
Edge Grasp Network: A Graph-Based SE(3)-invariant Approach to Grasp Detection
标题:边缘抓取网络:一种基于图的SE(3)不变的抓取检测方法
作者团队:Northeastern University(美国东北大学)
期刊会议:ICRA
时间:2023
代码:https://github.com/HaojHuang/Edge-Grasp-Network
一、目标问题
以单个视角观察到的点云为输入,得到一组抓取姿态
二、方法
(1)裁剪点云
给定一个点云p和接近点pa,只有接近点pa的相邻点会影响抓取,因此以pa为中心裁剪一个球。
(2)PointNet卷积
使用PointNet计算接近点与最近邻点,每个点的特征。
(3)计算全局特征
将逐点特征传递给MLP,用最大池化层生成一级全局特征。这些全局特征再与点特征相连传递到第二个MLP计算全局特征。
对于每个抓取,通过将全局特征与点特征连接来计算边缘特征,用分类器表示边缘抓取。
(4)抓取评估
使用sigmoid函数的四层MLP来预测抓取成功率,以边缘特征为输入计算抓取是否成功。
三、思考
该方法类似于DenseFusion的思想,即提取逐点特征和全局特征,进行特征融合,本文得到的融合特征即边缘特征,利用该特征再使用分类器得到抓取位姿。
 微信支付
微信支付 支付宝
支付宝