【论文笔记】ACT 使用低成本硬件的双手操作模仿学习
一、论文笔记
标题:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
中文标题:使用低成本硬件学习细粒度双手操作
作者团队:Stanford University
期刊会议:arXiv
时间:2023
代码:https://github.com/tonyzhaozh/act
1.1 目标问题
对于机器人而言,学习实现一些精细操作是较为困难的,因为涉及精确的力控以及闭环视觉反馈,这有需要先进的机器人,精确的传感器和准确的标定。
能否使用低成本、不精确的硬件来执行这些精细的操作任务?
1.2 方法
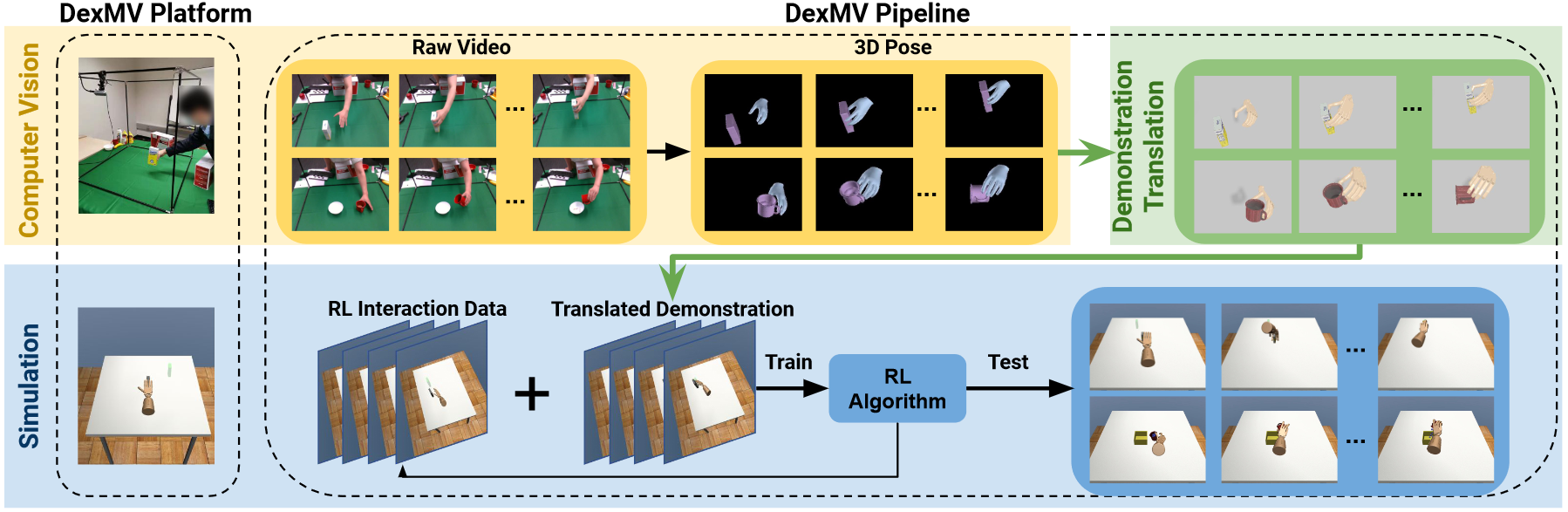
本文提出了一种简单的算法,ACT (Action Chunking with Transformers)。
首先使用 ALOHA 收集人类演示的引导机器人的关节位置,并将其作为动作,观测结果由机器人的当前关节位置和相机的输入图像组成。然后训练 ACT 根据当前观测预测未来的动作序列,也就是下一个时间步中双臂的目标关节位置。
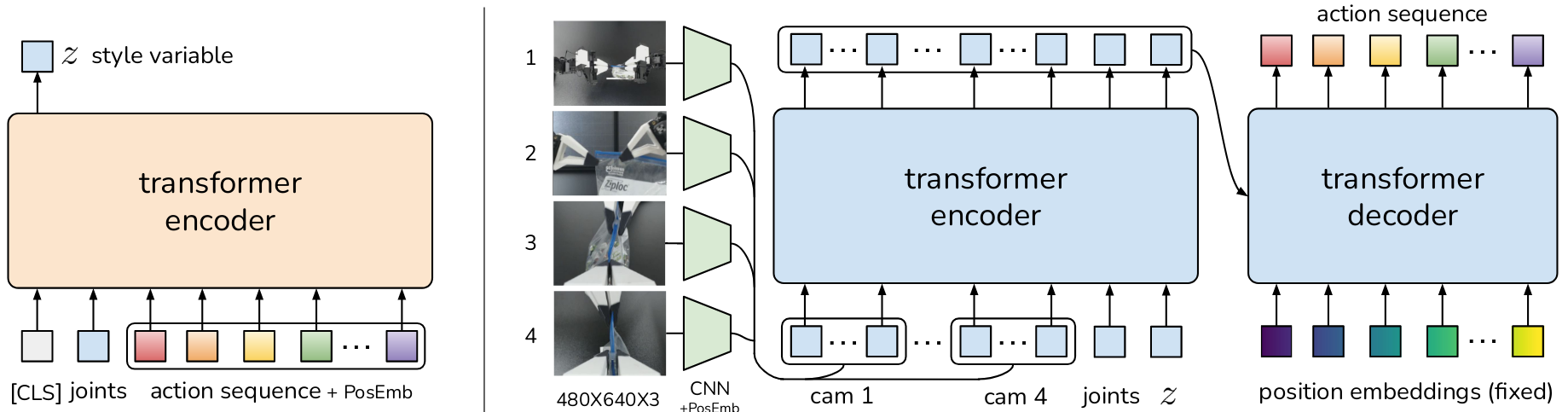
(1)动作分块和时间集成
为了利用像素到动作的策略,通过对抗模仿学习解决复合错误。本文使用了动作分块的思想,将多个动作分组在一起平作为一个单元执行,从而使他们更有效的存储和执行。
本文将动作块的大小固定为 k ,每 k 步,智能体接收一个观测结果,生成接下来的 k 个操作,并按顺序执行这些操作,因此任务的有效范围被减小了 k 倍。
但是这种方法得到的动作块可能不是最理想的动作,因此可能导致机器人的运动不稳定。为了提高平滑型,本文在每个时间步内执行策略,得到不同的动作块相互重叠,因此会有多个预测动作,本文对这些预测进行指数加权 $w_i=exp(-m*i)$,其中 $w_0$ 是最旧的动作的权重,$m$ 越小则合并的速度越快。
(2)人类数据建模
人类可以从不同个轨迹来解决同一个任务,尤其是在不要求精度的区域,人类的动作会非常随机,因此策略重点关注高精度区域也是非常重要的。
本文将策略训练为条件变分自动编码器 CVAE 来生成当前观测为条件的动作序列。
- CVAE 编码器:输入当前观测(机器人本体状态)和动作序列,编码后得到变量 z 分布,将其参数化为高斯分布,输出该分布的均值和方差
- CVAE 解码器:以 z 和当前观测(图像+机器人本体状态)为条件,预测动作序列。
二、代码复现 (act)
该部分参考论文原仓库:https://github.com/tonyzhaozh/act
2.1 环境准备
创建虚拟环境并安装依赖
1 | conda create -n aloha python=3.8.10 |
2.2 数据收集
首先激活虚拟环境
1 | conda activate aloha |
进入到代码根目录
1 | cd <path to act> |
创建两个目录,分别用于保存数据集和训练好后的模型
1 | mkdir -p datasets/sim_transfer_cube_scripted |
以 sim_transfer_cube_scripted 任务为例,使用下面的脚本产生 50 个 episodes 的数据(可以添加 --onscreen_render 来实现实时渲染):
1 | python3 record_sim_episodes.py --task_name sim_transfer_cube_scripted --dataset_dir datasets/sim_transfer_cube_scripted/ --num_episodes 50 |
产生的 50 个数据会以 50 个 hdf5 文件的格式保存在文件夹中,要想可视化这些数据集,可以使用下面的命令,以可视化第一个数据为例
1 | python3 visualize_episodes.py --dataset_dir datasets/sim_transfer_cube_scripted/ --episode_idx 0 |
2.3 训练
首先需要修改 constants.py 中的 DATA_DIR 参数,将其改为自己的数据集文件夹名称:
1 | DATA_DIR = '/home/mahaofei/Programs/Imitation/act/datasets' |
开始训练:
1 | python3 imitate_episodes.py --task_name sim_transfer_cube_scripted --ckpt_dir checkpoints/ --policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 --num_epochs 2000 --lr 1e-5 --seed 0 |
如果 ACT 策略在一个 episode 中是不稳定的或者是停止不变的,那么就训练更长时间,在平台期过后成功率和轨迹平滑性都会得到提高。
2.4 评估
还是和训练使用同一个脚本,只不过需要加入 --eval,该程序会把评估过程中的视频保存到 checkpoints 文件夹中,也可以添加 --onscreen_render 在评估是实时渲染。
1 | python3 imitate_episodes.py --task_name sim_transfer_cube_scripted --ckpt_dir checkpoints/ --policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 --num_epochs 2000 --lr 1e-5 --seed 0 --eval |
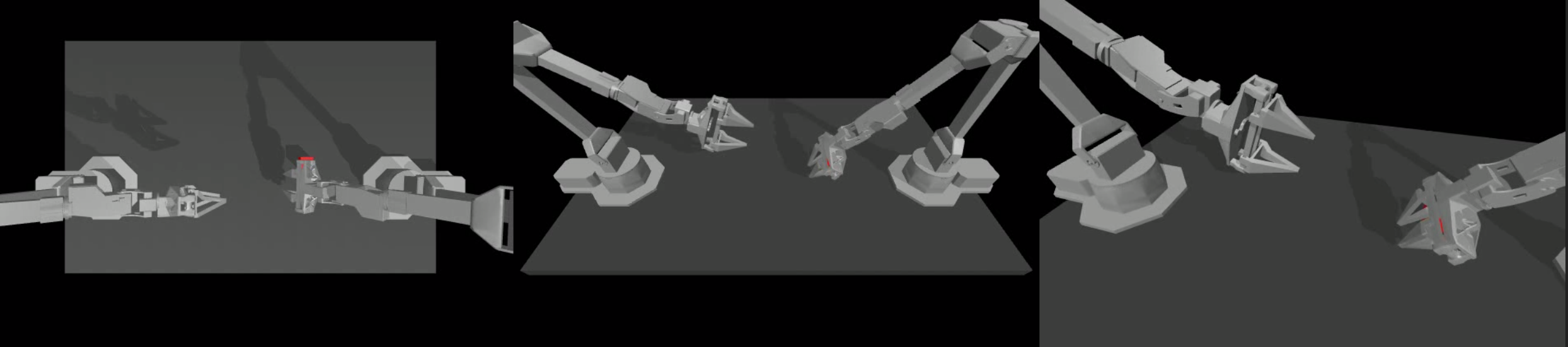
经测试,实际成功率并不高,在抓取时总会出现错位,且传递过程很难成功。
~~暂未知原因,等待后续检查。~~已查明原因,需使用特定版本的 mujoco,参考 issue #12
1 | pip install mojoco==2.3.7 dm_env==1.6 dm_control==1.0.14 |
三、代码复现 (act-plus-plus)
最近发现作者在一篇新的论文中 Mobile ALOHA Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,对 ACT 算法进行了更新,基本复现流程一致,部分进行了修改。
该部分参考论文原仓库:https://github.com/MarkFzp/act-plus-plus
2.1 环境准备
下载源码
1 | git clone https://github.com/MarkFzp/act-plus-plus |
创建虚拟环境并安装依赖
1 | conda create -n act python=3.8.10 |
实际上没有提到但却调用的库还有
1 | pip install diffusers |
修改 constants.py 中的 DATA_DIR 参数,将其改为自己的数据集文件夹名称:
1 | DATA_DIR = '/home/mahaofei/Programs/Imitation/act/datasets' |
在 wandb 官网创建账号,并创建一个项目,将 imitate_episodes.py 的第 148 行修改为
1 | wandb.init(project="项目名称", reinit=True, entity="wandb用户名", name=expr_name) |
截至 2023-01-05 开源的代码还存在一些问题,需要修改 detr/models/detr_vae.py 的第 285 行为 encoder = build_encoder(args),参考 issue
2.2 数据收集
首先激活虚拟环境
1 | conda activate act |
进入到代码根目录
1 | cd <path to act> |
创建两个目录,分别用于保存数据集和训练好后的模型
1 | mkdir -p datasets/sim_transfer_cube_scripted |
收集数据:以 sim_transfer_cube_scripted 任务为例,使用下面的脚本产生 50 个 episodes 的数据(可以添加 --onscreen_render 来实现实时渲染):
1 | python3 record_sim_episodes.py --task_name sim_transfer_cube_scripted --dataset_dir datasets/sim_transfer_cube_scripted/ --num_episodes 50 |
可视化收集的数据:产生的 50 个数据会以 50 个 hdf5 文件的格式保存在文件夹中,要想可视化这些数据集,可以使用下面的命令,以可视化第一个数据为例
1 | python3 visualize_episodes.py --dataset_dir datasets/sim_transfer_cube_scripted/ --episode_idx 0 |
2.3 训练
开始训练:
1 | python3 imitate_episodes.py --task_name sim_transfer_cube_scripted --ckpt_dir checkpoints/ --policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 4 --dim_feedforward 3200 --num_steps 2000 --lr 1e-5 --seed 0 |
如果爆显存了(CUDA out of memory),可以减小 batch_size。
如果 ACT 策略在一个 episode 中是不稳定的或者是停止不变的,那么就训练更长时间,在平台期过后成功率和轨迹平滑性都会得到提高。
2.4 评估
还是和训练使用同一个脚本,只不过需要加入 --eval,该程序会把评估过程中的视频保存到 checkpoints 文件夹中,也可以添加 --onscreen_render 在评估是实时渲染。
1 | python3 imitate_episodes.py --task_name sim_transfer_cube_scripted --ckpt_dir checkpoints/ --policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 --num_steps 10000 --lr 1e-5 --seed 0 --eval --onscreen_render |
三、代码解析
3.1 训练数据格式
ACT 的训练数据生成为多个 hdf5 文件,每个文件对应一个演示数据,每个 hdf5 文件的结构如下:
- episode_1.hdf5
- action: dateset 数据,存储机器人的动作,shape 为 (400, 14),包括末端执行器的位置和四元数,归一化的夹爪位置(0 关闭,1 打开)
[left_arm_qpos (6), left_gripper_positions (1), right_arm_qpos (6), right_gripper_positions (1),], - observations: group 组,存储观测数据
- images: gropu 组,存储图像数据
- left_wrist:dataset 数据,存储左侧机器人末端相机图像数据,shape 为 (400, 480, 640, 3),即长度 400,每个图像为 (480, 640, 3) 大小。
- right_wrist:dataset 数据,存储右侧机器人末端相机图像数据,shape 为 (400, 480, 640, 3),即长度 400,每个图像为 (480, 640, 3) 大小。
- top:dataset 数据,存储顶部相机图像数据,shape 为 (400, 480, 640, 3),即长度 400,每个图像为 (480, 640, 3) 大小。
- qpos:dateset 数据,shape 为 (400, 14),包括绝对关节位置,归一化的夹爪位置(0 关闭,1 打开)
[left_arm_qpos (6), left_gripper_position (1), right_arm_qpos (6), right_gripper_qpos (1)] - qvel:dateset 数据,shape 为 (400, 14),包括绝对关节速度(rad),归一化的夹爪速度(正数为正在打开,负数为正在关闭)
[left_arm_qvel (6), left_gripper_velocity (1), right_arm_qvel (6), right_gripper_qvel (1)]
- images: gropu 组,存储图像数据
- action: dateset 数据,存储机器人的动作,shape 为 (400, 14),包括末端执行器的位置和四元数,归一化的夹爪位置(0 关闭,1 打开)
3.2 替换 Gym 环境
(1)补充依赖
1 | pip install gym==0.12.1 |
(2)编写脚本生成与 ACT 训练数据格式相同的 HDF5 数据
(3)进行训练
 微信支付
微信支付 支付宝
支付宝