Transformer图像分类、图像分割与ConvNeXt 原理
一、Transformer基础
Transformer最开始是用于NLP自然语言处理的,例如RNN的记忆长度较短,LSTM无法并行化推理。
(1)Self-Attention模块
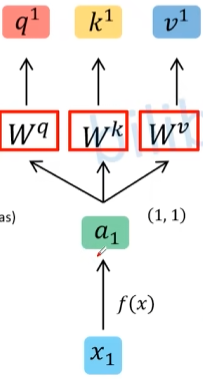
例如,给定输入 $x_1,x_2$ ,通过Embedding处理得到 $a_1,a_2$ 两个向量。
定义三个参数矩阵 $W^q,W^k,W^v$,将参数矩阵乘以所有向量,得到 $q_1,q_2,k_1,k_2,v_1,v_2$。
q:$q^i=a^iW^q$,query,后续会去和每一个k进行匹配k:$k^i=a^iW^k$,key,后续会被每个q匹配v:$v^i=a^iW^v$,代表从a中提取的信息
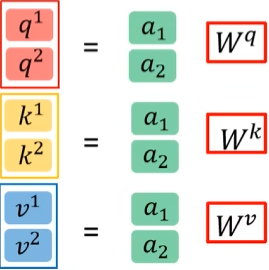
将所有的 $q_i$ 按列放置得到 $Q$,同理得到$K,V$,即:
$$
Q=A\cdot W^q=[q^1,q^2\dots]^T
$$
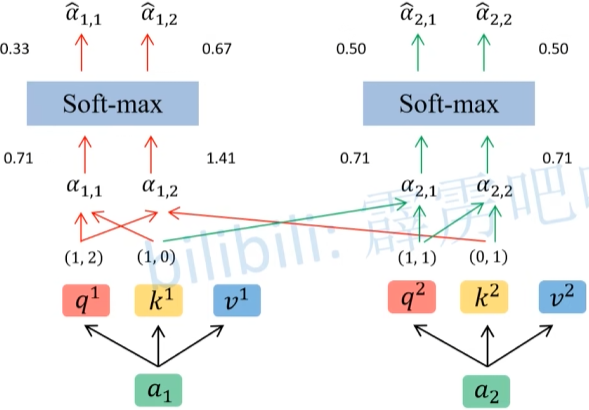
将得到的 q 与每一个 k 进行 match,match 计算方法如下:
$$
\alpha_{i,j}=\frac{q^i\cdot k^j}{\sqrt{d}}
$$
其中 $d$ 代表向量 $k^i$ 的长度,得到的值 $\alpha$ 就代表 $q$ 和 $k$ 的相关性,值越大相关性越大。
写成矩阵形式如下:
$$
\left[\begin{array}{c}
\alpha_{1,1} & \alpha_{1,2} \
\alpha_{2,1} & \alpha_{2,2}
\end{array}\right]=\frac{Q\cdot K^T}{\sqrt{d}}
$$
对得到的$\alpha$矩阵每一行进行Soft-max处理得到$\hat \alpha$。
然后利用得到的相关性,从v中提取特征
$$
b_i=\sum_j \hat a_{i,j} v_j
$$
写成矩阵形式为
$$
B=\left[\begin{array}{c}
\hat \alpha_{1,1} & \hat \alpha_{1,2} \
\hat \alpha_{2,1} & \hat \alpha_{2,2}
\end{array}\right]\cdot V
$$
最终整个Self-Attention模块可以抽象为以下公式:
$$
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
$$
(2)Multi-head Self-Attention
相比较于 Single-head,Multi-head将得到的 $q_1$ 变成了 $q_{1,1}$ 其中后一个数字代表head1的数据,对每一个head进行单独的self-attention过程,得到 $b_{1,1}$,最后将 $b$ 中第一个数字相同的向量进行拼接。
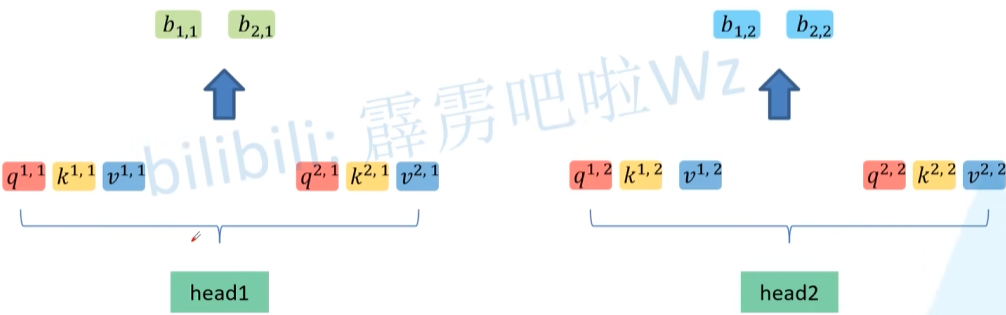
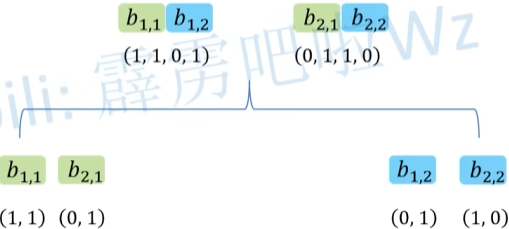
最后对拼接后的数据进行进一步融合,其中的 $W^O$ 是需要学习的参数。
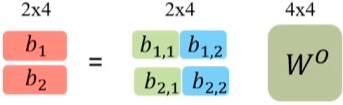
二、Vision Transformer 原理
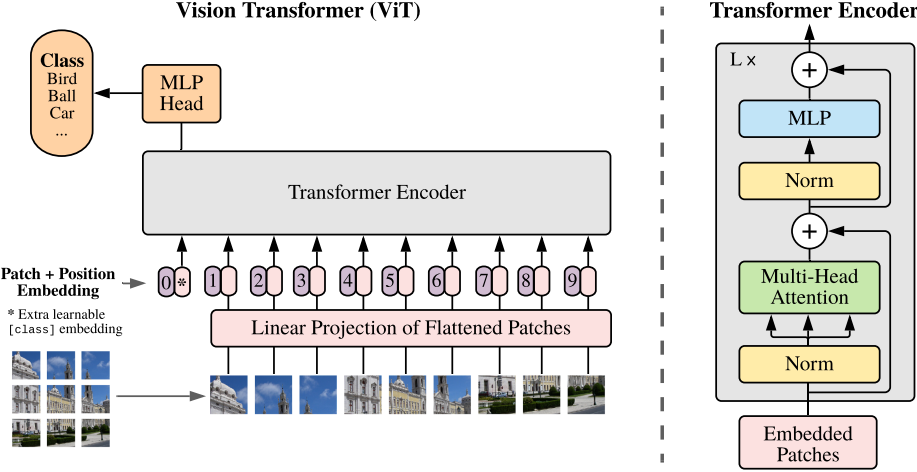
- ViT将一张图片分成多个patches
- 将每一个Patches输入到Embedding层(Linear Projection of Flattened Patches),得到一系列token
- 在所有token前增加一个用于分类的class token (
*),其维度与其它token相同 - 为所有token增加位置信息(
0,1,...,9) - 将token输入到
Transformer Encoder中,获取class token对应的输出 - 利用MLP Head获得分类信息。
(1)Embedding层
对于标准的 Transformer 模块,要求输入的是 token 序列,即二维矩阵 [num_token, token_dim]。
代码中直接使用一个卷积层来实现,例如分割后的 patch 为 [224,224,3],经过k=16,s=16卷积后变为 [14,14,768],再将其展开为 [196,758] 作为 token。
拼接 class token 后,变为 [197,768]。
叠加位置编码后,token 维度仍然为 [197,768](位置编码直接矩阵相加)
(2)Transformer Encoder层
文中的 Transformer Encoder 层就是将 Transformer Encoder 模块重复 L 次。
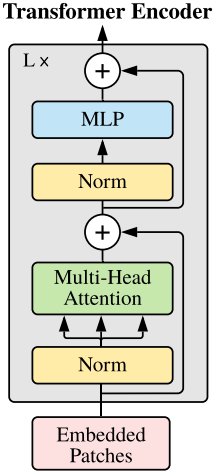
首先对输入的 token 进行 Layer Normorlization,然后经过 Multi-Head Attention,然后经过一次 Dropout,得到的结果与输入的 token 相加,得到一个输出。
然后经过一个Layer Norm,MLP(由全连接层->GELU->Dropout->全连接层->Dropout),最后经过Dropout,得到的结果与上面的输出相加,最终得到 Transformer Encoder 模块的输出。
最后如果要用于图像分类,只需要切片获得输出的第一个向量 class token。(相当于使用 Transformer 计算 class token 和其它 token 特征之间的相关度,相关度最高的即为预测分类)
(3)MLP Head 层
训练 ImageNet21K 等复杂数据集时,由Linear+tanh+Linear组成。
实际训练自己数据集时,只使用一个全连接层Linear即可。
ConvNeXt 原理
由 Meta 和 UC Berkeley 于 2022 年提出的卷积神经网络,对比 Transformer。
该论文的主要思路是利用于 Swin-Transformer 类似的方式,调整网络结构,使传统的卷积神经网络也能达到很好的效果。
(1)Macro design
- 将 ResNet-50 中的堆叠层数由 (3,4,6,3) 调整为 (3,3,9,3)
- 将 stem 换成卷积核大小为 4,步距为 4 的卷积层。(对应下采样过程,ResNet 中为 7x7, 64, stride 2 的卷积层)
- 将 ResNet 中的卷积部分修改为 depthwise convolution
- ReLU 激活函数替换为 GELU(准确率未变化)
- 使用更少的激活函数(准确率提高)
- 使用更少的归一化层
- 用 LN 替换 BN
(2)Inverted bottleneck
作者认为 Transformer block 中的 MLP 模块与 MobileNetV2 中的 Inverted Bottleneck 模块非常相似。因此也将瓶颈类结构更换为两头细中间粗结构。
(3)Large Kerner size
将 depthwise conv 模块上移,并增加了 kernel size。
 微信支付
微信支付 支付宝
支付宝