【论文笔记】CVPR2020-2022 6D位姿估计相关论文
CVPR 2020
01. HybridPose: 6D Object Pose Estimation under Hybrid Representations
期刊 / 会议:CVPR2020
作者 / 机构:Chen Song, The University of Texas at Austin
关键词:位姿估计;混合特征
时间:2020
代码:https://github.com/chensong1995/HybridPose
1 目标问题
6D位姿估计
2 方法

算法由中间特征预测网络和姿态回归网络组成:
(1)预测模块
将图像作为输入,用三个预测网络输出预测的关键点、边缘向量和对称对应关系
- 关键点:利用PVNet的关键点预测方法
- 边缘向量:每两个关键点之间的向量
- 对称对应关系:扩展了FlowNet网络,结合了像素流和语义掩码
(2)姿态回归模块
姿态回归网络:包括初始化子模块和优化子模块
- 初始化子模块:使用中间特征回归初始姿态
- 优化子模块:使用GM鲁棒范数并优化,获得最终姿态
3 思考
方法比较直观,使用关键点、关键点向量和对称关系进行姿态预测。
但是实际应用比较困难,训练前需要使用FSP生成关键点标签、使用SymSeg生成对称性标签,并且还要提供分割模板。而且还需要PVNet的融合数据。
02. Single-Stage 6D Object Pose Estimation
期刊 / 会议:CVPR2020
作者 / 机构:Yinlin Hu, CVLab, EPFL, Switzerland
关键词:位姿估计;单阶段
时间:2020
代码:https://github.com/cvlab-epfl/single-stage-pose
1 目标问题
提出一种单阶段框架,解决两阶段框架(先建立3D对象关键点和2D图像的对应关系然后回归)的缺点,加快训练速度。
2 方法
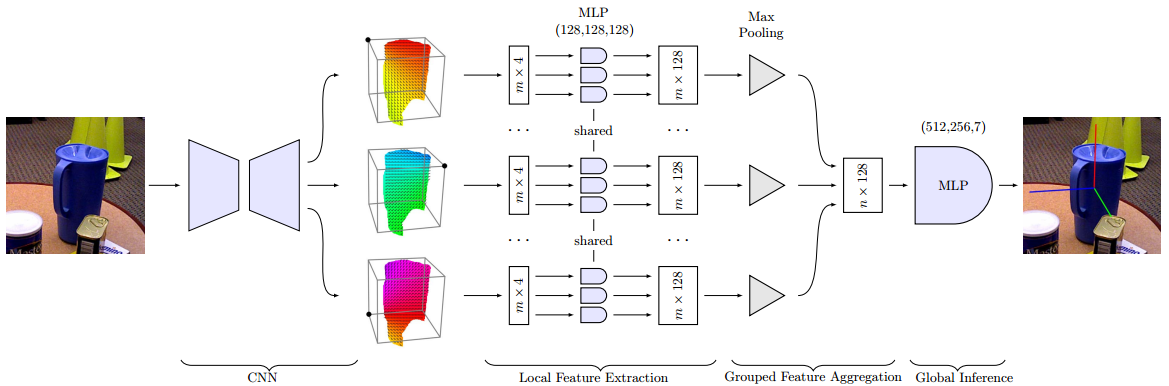
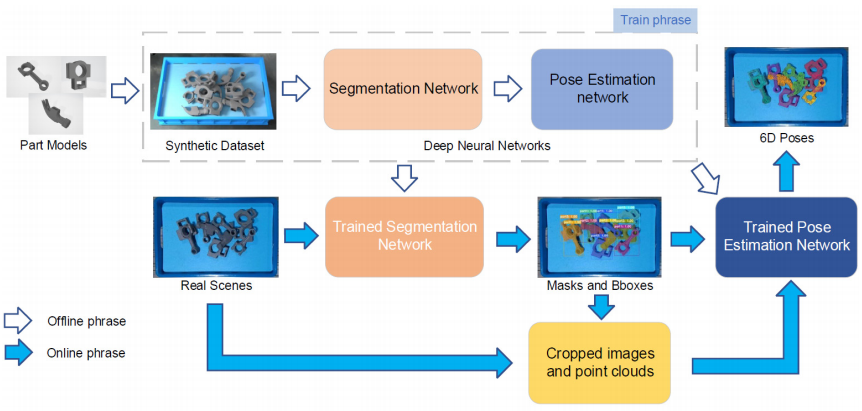
通过一些实例分割网络建立了3D物体和2D图像的关系后,使用三个主要模块来直接从这些对应聚类预测位姿:
-
局部特征提取模块
-
特征聚合模块:在不同聚类中聚合特征
-
全局推理模块:有全连接层组成,用于将最终姿态估计为四元数和平移
-
提出了一种新颖的投影分布(Projection Distribution)表示法,将三维物体关键点在二维图像上的投影建模为一个概率分布,而不是一个确定的位置。
-
设计了一个单阶段6D姿态估计网络(Single-Stage 6D Pose Estimation Network),利用卷积神经网络和全连接层来预测每个物体关键点在图像上的投影分布参数。
-
采用了一种最大似然估计(Maximum Likelihood Estimation)方法,根据预测的投影分布参数和已知的三维物体模型来直接计算物体在相机坐标系下的旋转矩阵和平移向量。
3 思考
似乎需要与其它网络结合,从其他网络的中间层进行特征提取。
Github资料较少。
03. G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features
期刊 / 会议:CVPR2020
作者 / 机构:Wei Chen, School of Computer Science, University of Birmingham
关键词:位姿估计
时间:2020
代码:https://github.com/DC1991/G2L_Net
1 目标问题
提高位姿估计算法的准确度和速度。
2 方法
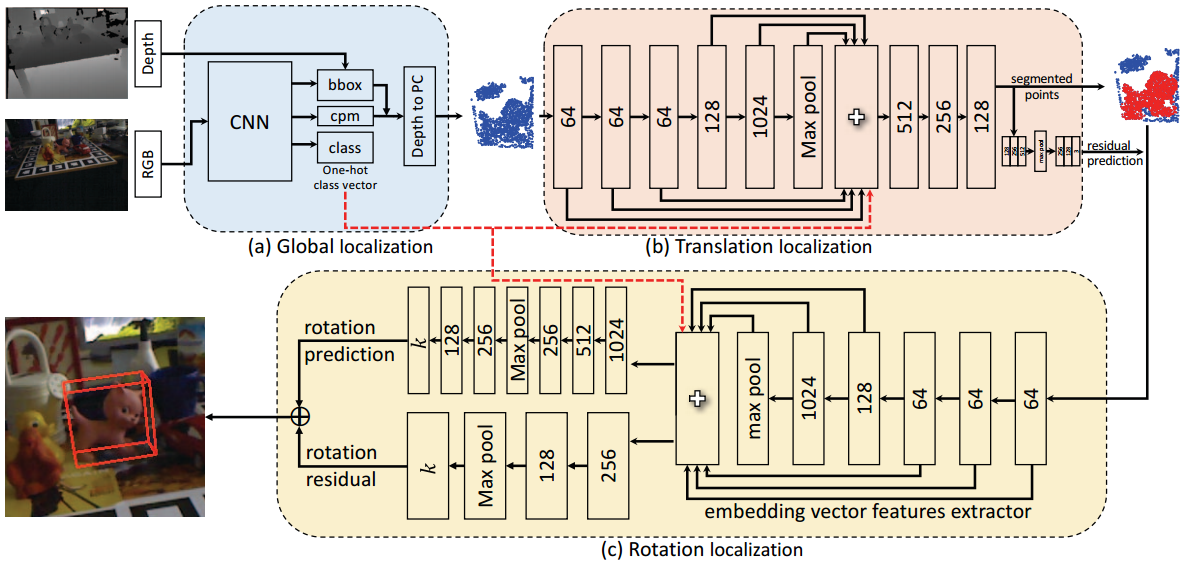
(1)全局定位
使用2D检测器(例如yolo)来预测目标的边界框和标签,并将得到的概率图中的最大概率位置作为球体中心(结合深度图的3D坐标),来获得一个球体空间,减少后续3D搜索空间。
(2)平移定位
进行3D分割和平移残差预测,并将对象点的坐标系转换为局部规范坐标系。
(3)旋转定位
使用逐点嵌入向量特征提取器来提取嵌入向量特征,然后输入解码器回归出输入点云的旋转。
3 思考
相当于将DenseFusion的实例分割先验步骤进行了替换,使用了yolo+点云分割来代替。最后的特征还是逐点特征。
CVPR2021
01. GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
期刊 / 会议:CVPR2021
作者 / 机构:Gu Wang, Tsinghua University, BNRist
关键词:位姿估计;端到端
时间:2021
代码:https://github.com/THU-DA-6D-Pose-Group/GDR-Net
1 目标问题
提出一种端到端的位姿估计算法。
2 方法
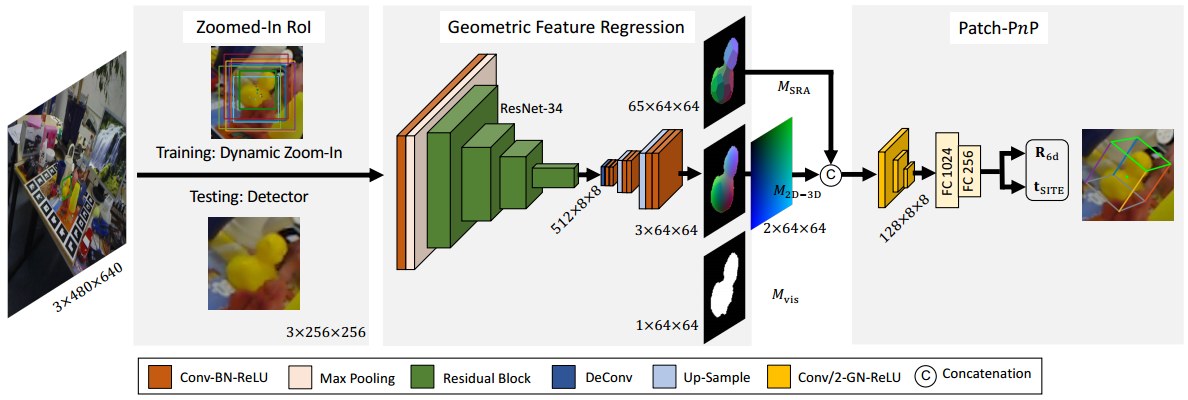
(1)网络架构
首先向GDR-Net提供256x256的ROI图,预测出三个64x64的中间特征图
- 稠密对应图$M_{2D-3D}$:将稠密坐标映射$M_{XYZ}$对跌倒2D像素坐标上得到,反映了对象的几何形状信息。
- 表面区域注意图$M_{SRA}$:采用最远点采样从$M_{XYZ}$中到处,代表了对象的对称性。
- 可见对象掩码$M_{vis}$
使用一个简单的2D卷积Patch Pnp模块直接从特征图中回归6D对象姿态。Patch PnP模块由三个卷积层组成,然后用两个全连接层用于扁平化特征,最后连个全连接层输出R6D旋转和tSITE平移。
3 思考
本文专注于图像的特征提取和处理工作,实现从单一图片预测位姿的功能。方法不够直观。
02. FS-Net: Fast Shape-based Network for Category-Level 6D Object Pose Estimation with Decoupled Rotation Mechanism
期刊 / 会议:CVPR2021
作者 / 机构:Wei Chen, School of Computer Science, University of Birmingham
关键词:位姿估计
时间:2021
代码:https://github.com/DC1991/FS_Net
1 目标问题
解决以往类别级姿态特征提取效率低,精度和推理速度低的问题。
2 方法
设计了一种具有3D图卷积的方向感知自动编码器,用于潜在特征提取。
提出解耦旋转机制,利用两个解码器互补的访问旋转信息。
使用两个残差来估计平移。
提出一种在线box-cage的三维变形机制来增强训练数据。
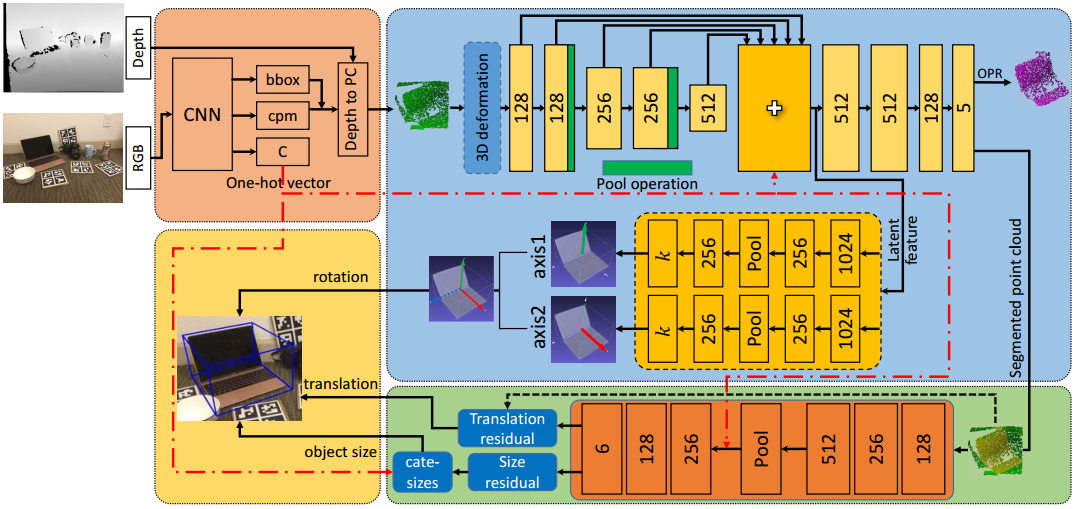
- 输入RGB图像。
- 使用yolov3检测对象的2D位置、类别标签、类概率图,并将最大概率的位置作为3D球体的中心。从而得到目标3D球体点云。
- 使用三维变形机制进行数据扩充。
- 使用基于形状的3DGC自动编码器来进行点云分割,用于旋转的潜在特征学习。
3DGC由m个单位向量组成,卷积值是核向量和n个最近向量之间的余弦相似度之和。 - 从潜在特征中将旋转信息解码为两个垂直向量。
- 利用残差估计网络预测平移。
3 思考
提出的使用三维变形机制进行数据扩充很有意思,或许后续很多方法都可以加上这个步骤,使得算法更具有鲁棒性。
需要训练yolo模型和FS_Net模型。
NOCS数据集
CVPR2022
01. OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
期刊 / 会议:CVPR2022
作者 / 机构:Dingding Cai, Tampere University
关键词:位姿估计
时间:2022
代码:https://github.com/dingdingcai/OVE6D-pose
1 目标问题
已知物体的分割掩码,物体的三维mesh模型,预测从物体坐标系到相机坐标系的变换R+T。
2 方法
(1)训练阶段
使用ShapeNet中的3D物体模型来训练OVE6D模型,这个阶段只进行一次,得到的模型参数在后续保持固定。
(2)编码阶段
将目标物体的3D网络模型转换为view points编码本,这个阶段对每个物体只进行一次。(view points编码本是一个特征向量的集合)
(3)推理阶段
从输入的物体深度图像和物体分割掩码中推理物体的6D姿态
- 视角估计:将输入图像和物体ID作为输入,通过与view points编码本中的特征向量进行余弦相似度匹配找到最接近的预定义视角,并输出索引和置信度。
- 平面旋转估计:输入图像、ID、预定视角索引、置信度,通过卷积神经网络回归出相对于相机坐标系的旋转。
- 平移估计:输入图像、ID、预定义视角索引、置信度、平面旋转角度,通过另一个卷积神经网络输出物体的3D位置。
3 思考
算法需要预先训练好ShapeNet,然后确定一个view points编码本,过程较复杂不够简洁直观。
02. OnePose: One-Shot Object Pose Estimation without CAD Models
期刊 / 会议:CVPR2022
作者 / 机构:Jiaming Sun, Zhejiang University
关键词:位姿估计
时间:2022
代码:https://github.com/zju3dv/OnePose
1 目标问题
实现不依赖于CAD模型的位姿估计
2 方法
借鉴了视觉定位的思想,只需要一个简单的RGB视频扫描物体,就可以构建一个稀疏的SfM模型。然后,利用一个通用的特征匹配网络将这个模型与新的查询图像对齐,从而得到物体姿态。
提出了一种新的图注意力网络(GATs),可以将同一个SfM点对应的2D特征聚合成3D特征,并与查询图像中的2D特征进行自注意力和交叉注意力匹配。
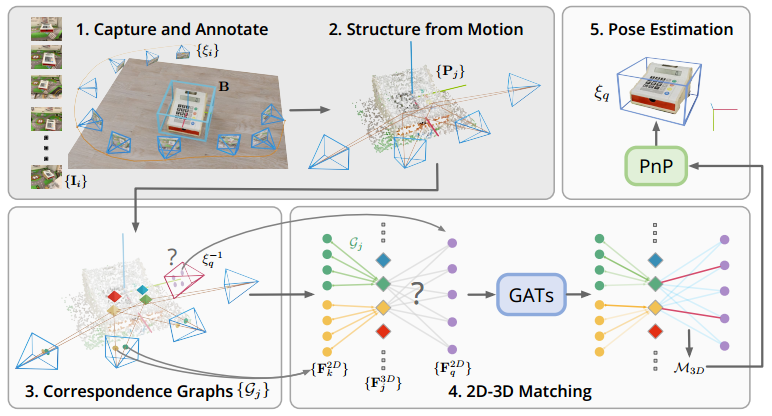
- 对于每一个物体,使用视频扫描得到一组相机姿态以及物体的3D边界框。
- 利用SFM重建一个稀疏的点云模型
- SfM的2D-3D对应关系被建立起来
- 使用注意力聚合层,将2D描述符聚合到3D描述符
- 通过PnP回归计算出物体位姿
总体实现流程如下
- 使用一些AR工具捕获物体数据,包括物体中心位置,尺寸,绕Z州的旋转角,相机姿态等。
- 从捕获的视频中提取图像,使用SfM重建稀疏点云,所有的对应图中提取2D关键点和描述符。
- 定位时,实时捕获一系列图像,提取2D关键点和描述符进行匹配,从数据库中查询候选图像,从而找到相机姿态。
3 思考
大概就是创建一个数据库,包括2D图像和重建出的点云,以及相应的2D-3D关键点和描述符,对每一个输入图像提取特征后进行匹配查询。
03. Focal Length and Object Pose Estimation via Render and Compare
期刊 / 会议:CVPR2022
作者 / 机构:Georgy Ponimatkin, LIGM, Ecole des Ponts, Univ Gustave Eiffel, CNRS
关键词:位姿估计
时间:2022
代码:https://ponimatkin.github.io/focalpose
1 目标问题
估计相机参数未知的照片中物体的6D姿态
2 方法
- 从一个3D模型库中选择一个与输入图像中物体最匹配的3D模型。
- 用一个CNN编码器将输入图像编码成一个特征向量。
- 用一个CNN解码器将特征向量解码成一个初始的6D姿态和焦距。
- 用渲染引擎根据初始的6D姿态和焦距渲染出一个虚拟视图,并与输入图像进行比较。
- 用一个损失函数计算虚拟视图和输入图像之间的差异,并反向传播更新6D姿态和焦距。
- 重复步骤4和5直到收敛或达到最大迭代次数。
3 思考
对于网络图像中物体的位姿估计,不知道实际应用场景是什么。
04. ES6D: A Computation Efficient and Symmetry-Aware 6D Pose Regression Framework
期刊 / 会议:CVPR2022
作者 / 机构:Ningkai Mo, ShenZhen Key Lab of Computer Vision and Pattern Recognition
关键词:位姿估计;对称
时间:2022
代码:https://github.com/GANWANSHUI/ES6D
1 目标问题
主要解决如何利用RGB-D数据来估计刚体物体的6D姿态,特别是对于具有对称性的物体
2 方法
- 设计了一个全卷积的特征提取网络,叫做XYZNet,它可以高效地从RGB和深度图中提取点云特征,并将不同模态的特征融合起来。
- 提出了一种新的形状表示方法,叫做分组基元(GP),它只与物体的对称性有关,而忽略了形状的细节。
- 基于GP,设计了一种新的姿态距离度量,叫做平均(最大)分组基元距离,或者A(M)GPD。这种度量可以作为损失函数来训练回归网络,并保证网络收敛到正确的姿态。
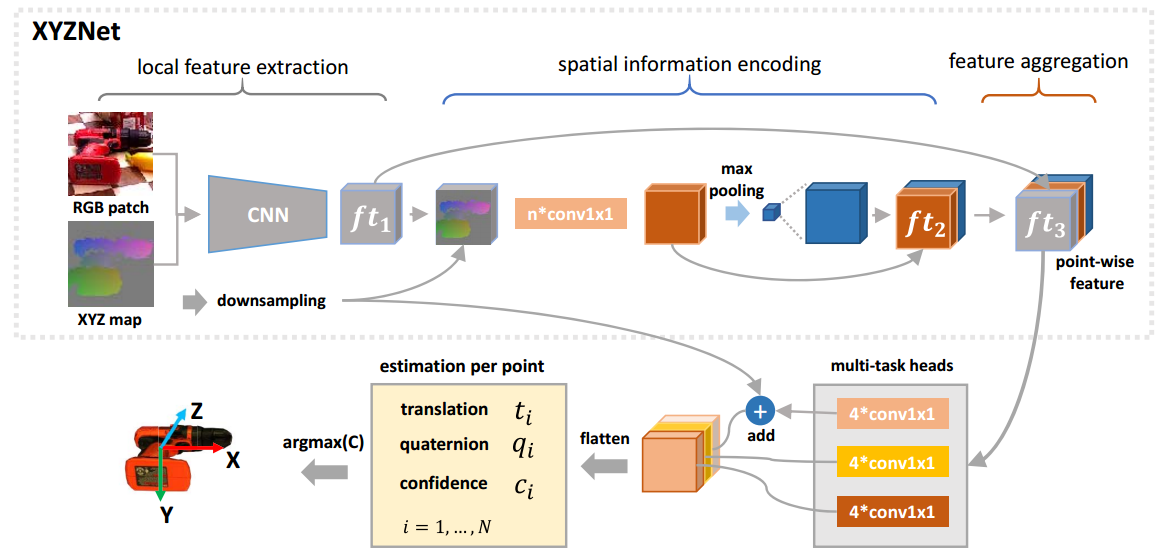
- 从RGB-D图像生成RGB-XYZ数据。RGB-XYZ数据被馈送到CNN模块以提取局部特征,该局部特征对颜色和几何信息进行编码
- 点云特征是通过类似PointNet的CNN模块获得的,并填充到与局部特征相同的大小
- 将局部特征和点云特征连接为用于姿态估计的逐点特征
- 选择具有最大置信度的姿势作为最终结果
3 思考
同样是逐点特征,这篇论文提出了XYZNet,可以更高效的提取提取点云和RGB特征,不需要提供掩码图。
代码只提供T-LESS数据集方法。
05. GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting
期刊 / 会议:CVPR2022
作者 / 机构:YanDi, Technical University of Munich
关键词:位姿估计
时间:2022
代码:https://github.com/lolrudy/GPV_Pose
1 目标问题
主要解决了现有方法在处理未见过的物体实例时存在的不确定性和不稳定性的问题
2 方法
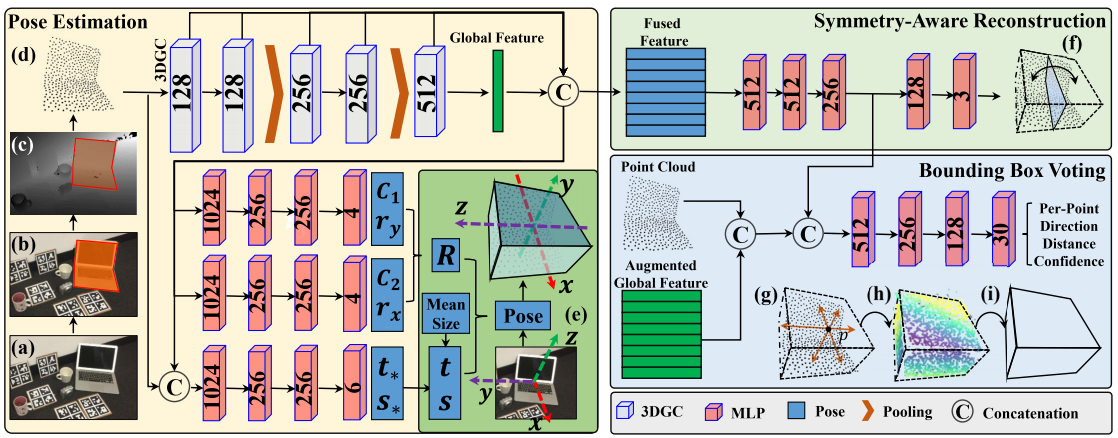
- 给定一副RGB-D图像,先使用如Maks-RCNN等方法将物体从深度图中分割出来。
- 然后从深度三维点云中抽取1028个点,并将它们输入到GPV-Pose位姿估计网络中。
- 由于3DGC对于点云的移动和缩放不敏感,所以以3DGC为主干提取全局和每个点的特征,凭借附加了三个并行分支,用于姿态预测,对称性,和逐点包围盒。
注:
- 3DGC方法首先将输入点云转换为一个k近邻图(kNN graph),其中每个点与其最近的k个邻居相连。使用多层图卷积(Graph Convolution)来提取每个点的局部特征,并使用最大池化(Max Pooling)来提取全局特征。3DGC方法将全局和逐点特征拼接起来,形成一个混合特征向量,用于后续的姿态估计、对称感知重建和点投票模块。
3 思考
(1)创新点
- 引入了一种解耦的置信度驱动旋转表示,允许几何感知恢复相关旋转矩阵
- 提出了一种基于点投票的位移估计模块,利用几何约束来生成可靠和精确的位移预测
- 在一个端到端可训练的网络中整合这两个模块,并通过一个多任务损失函数进行优化
(2)与DenseFusion相比
它们都使用了3D图卷积网络(3DGC)来从输入点云中提取每个点的局部特征,并将其与全局特征拼接起来,形成一个混合特征向量。
GPV-Pose使用了一种解耦的置信度驱动的旋转表示,可以通过几何关系恢复旋转矩阵,而DenseFusion使用了一种直接预测四元数的方法。
使用NOCS数据集。
06. DGECN: A Depth-Guided Edge Convolutional Network for End-to-End 6D Pose Estimation
期刊 / 会议:CVPR2022
作者 / 机构:Tuo Cao, School of Computer Science, Wuhan University, Wuhan, Hubei, China
关键词:位姿估计
时间:2022
代码:https://github.com/maplect/DGECN_CVPR2022
1 目标问题
从单目RGB图像中进行位姿估计。
2 方法
(1)深度细化网络DRN
两个不同的深度估计网络分别输出深度图DA和DB,计算两个深度图之间的差异,并将差异超过阈值的区域定义为不确定区域。
(2)特征提取
- 深度估计:将彩色图像作为输入,并执行深度图预测
- 对象分割:利用分割的掩码,将深度图转换为3D点云,并利用3D特征提取器来提取几何特征
(3)2D关键点定位
采用最远点采样(FPS)算法来选择物体表面上的关键点。
(4)从2D-3D对应关系学习6D位姿
使用动态图PnP(DG-PnP)算法,通过边缘卷积构建一个图结构,利用2D-3D对应关系中的拓扑信息来直接学习6D姿态
3 思考
(1)创新点
- 用一个深度引导网络同时预测分割和深度图,并用一个深度优化网络(DRN)提高深度图的质量
- 根据分割和深度图建立2D-3D对应关系,即将图像上的关键点与3D模型上的点匹配
- 提出一个动态图PnP(DG-PnP)算法,通过边缘卷积构建一个图结构,利用2D-3D对应关系中的拓扑信息来直接学习6D姿态
(2)实用性
从单目RGB图像进行位姿估计,通过网络回归深度图。
07. Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions)
期刊 / 会议:CVPR2022
作者 / 机构:Van Nguyen Nguyen, LIGM, Ecole des Ponts, Univ Gustave Eiffel, CNRS, France
关键词:位姿估计
时间:2022
代码:https://github.com/nv-nguyen/template-pose
数据集:LINEMOD
1 目标问题
提出了一种方法,只需要物体的CAD模型,就可以将输入对象匹配到一组模板,即使在部分遮挡的情况下也可以估计3D姿态。
2 方法
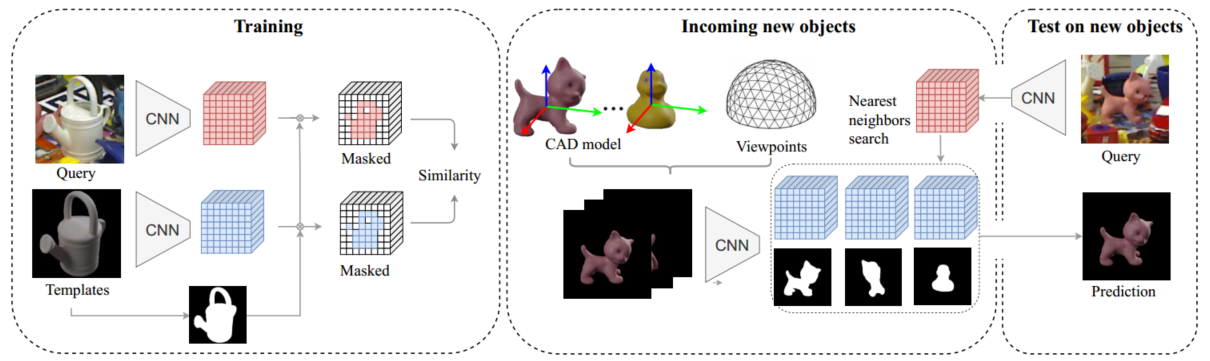
训练时,使用由真实图像和合成模板组成的对,来计算局部特征,预测两幅图像的相似性。
然后对于未看到的图像,计算其局部特征,将图像与模板数据库匹配来检索对象姿态。
3 思考
编码本思想,实用性较强,可尝试。
08. Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
期刊 / 会议:CVPR2022
作者 / 机构:Lahav Lipson, Princeton University
关键词:位姿估计;迭代优化
时间:2022
代码:https://github.com/princeton-vl/Coupled-Iterative-Refinement
数据集:LINEMOD
1 目标问题
给定一组已知的RGBD输入,检测每个对象的6D姿态。
2 方法
算法复杂,迭代优化方法。
3 思考
代码效果最好,但是代码较为复杂。
 微信支付
微信支付 支付宝
支付宝