【6D位姿估计算法】Gen6D算法
论文笔记
标题:Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images
作者团队:The University of Hong Kong
期刊会议:ECCV
时间:2022
代码:https://github.com/liuyuan-pal/Gen6D
1. 介绍
1.1 目标问题
现有的位姿估计算法要么需要高质量的物体模型,要么需要提供额外的深度图或物体掩码图,这对于位姿估计的实际应用有很大的限制。本文提出的方法只需要一些物体的姿态图像,就能够在任意环境中预测物体位姿。
作者认为一个位姿估计器应该具有以下特点:
- 通用性:可以应用于任意物体,而无需对对象或类别进行训练
- 无模型:用于一个未见过的物体时,只需要一些已知姿态的参考图像来定义物体参考坐标系即可
- 输入简单:仅输入RGB图像来估计位姿,而不需要深度图或物体掩码图
(1)如何设计视角选择器,从参考图像中找到与查询图像视角最接近的
本文使用神经网络对查询图像和参考图像进行逐像素比较,产生相似性得分,并选择具有最高相似性得分的参考图像。并添加了全局归一化层和自注意层来共享不同参考图像之间的相似性信息,为选择最相似的参考图像提供了上下文信息。
(2)实现没有模型的姿态优化
本文提出了一种新的基于三维空间的姿态优化方法,给定一个查询图像和一个输入姿态,找到几个接近输入姿态的参考图像,将这些参考图像投影回3D空间中,构建特征空间,通过3D的CNN将构建的特征空间与查询图像的特征相匹配,来优化姿态。
1.2 现有工作
现有位姿估计方法大都是基于特定实例的,不能推广到未见过的物体,通常都需要根据物体3D模型来渲染大量图像进行训练。有一些方法可以推广到类别级,也不需要对象的模型,但仍然无法预测没见过的类别的物体。
2. 实现方法
数据规范化:对于每个物体,通过对参考图像中的点进行三角测量等方法估计物体的大致大小,然后对物体坐标系进行归一化,使物体中心位于原点,大小为1,此时物体位于原点的单位球体内。
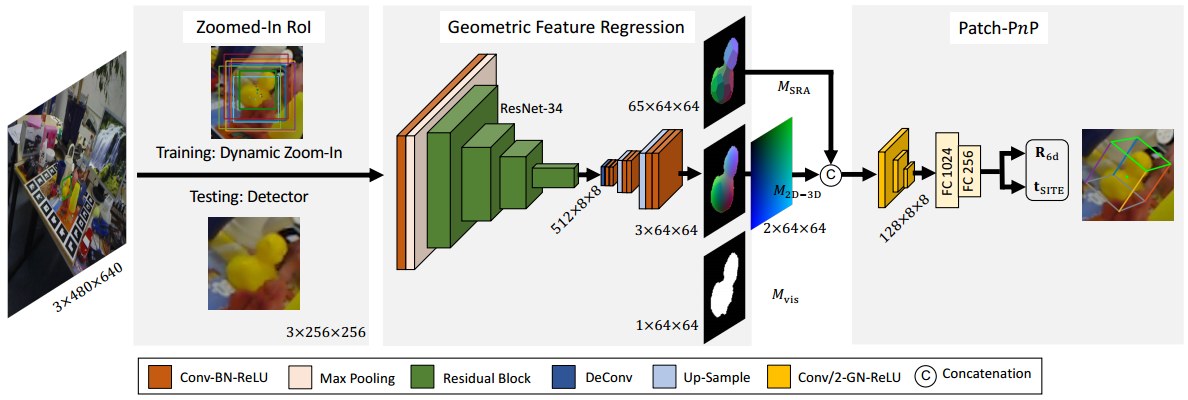
Gen6D包括一个物体检测器,一个视角选择器,一个姿态优化器。

物体检测其首先利用查询图像和参考图像来检测物体所在区域。然后视角选择器将查询图像于参考图像相匹配,产生粗略的初始姿态。最后由姿态优化器进一步细化以得到精确的对象姿态。
2.1 物体检测
将检测问题分解成两部分
- 找到对象中心的2D投影点q
- 估计包围单位球体的正方形边界框。
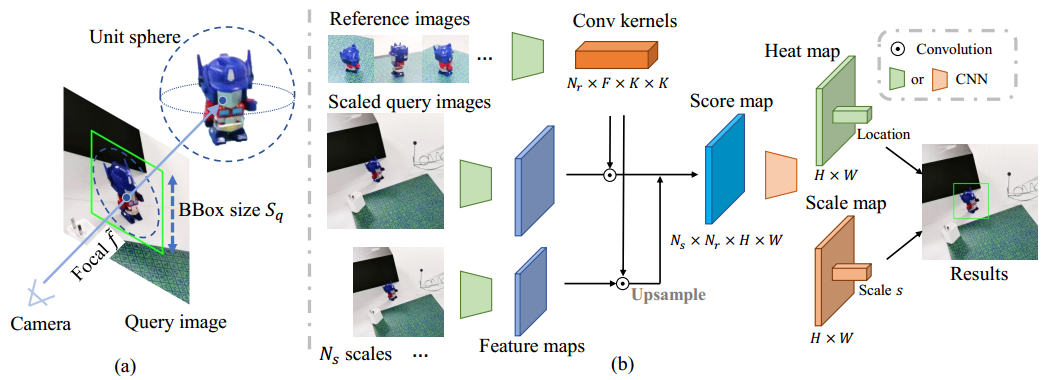
物体中心的深度可以使用$d=2f/S_q$求得,其中2是单位球体的直径,f是虚拟焦距(将主点设为投影点q),$S_q$是边界框边长。这就是物体的初始平移。
问题:这里将物体归一化之后求出的深度d还是真实深度吗?虚拟焦距又是如何确定的?
检测器使用了VGG网络提取参考图像和查询图像的特征图,然后将所有参考图像的特征图作为卷积核与查询图像的特征图卷积,得到分数图。考虑尺度差异,设置再多个预定义尺度上进行卷积,最后得到热力图和比例图。选择热力图上的最大值位置作为对象中心2D投影,使用比例图上相同比例的比例作为边界框的大小$S_q=S_r*s$。
问题:这里将所有参考图像的特征图都进行卷积,那么参考图像上物体特征和背景特征是如何区分的?
2.2 视角选择
将查询图像与每个参考图像比较,计算相似性得分。计算每个参考图像和查询图像的元素乘积,获得得分图,并计算相似性参数。

(1)平面内旋转
为了考虑平面内旋转,本文将参考图像旋转Na个预定义角度,查询时使用所有旋转版本进行逐元素乘积。
(2)全局归一化
使用参考图像的所有特征图计算的均值和方差,对相似度网络生成的特征图进行归一化。这样做可以用特征图的分布来编码上下文相似性,并放大不同图像之间的相似性差异。
(3)参考视角变换
在所有参考图像的相似性特征向量上应用变换,包括它们的视角、注意力层。这样的变换器使得特征向量相互通信以编码上下文信息,有助于确定最相似的参考图像。
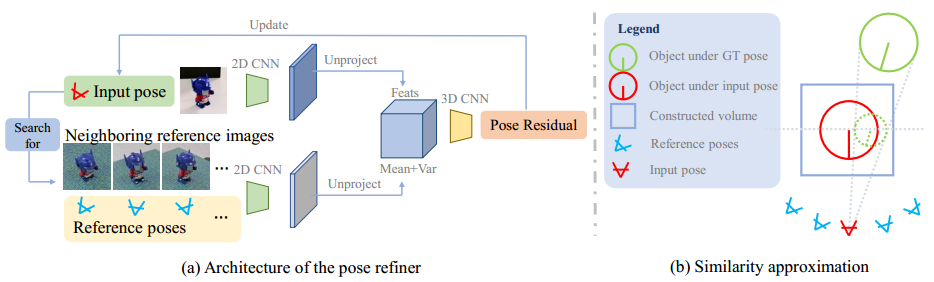
2.3 姿态优化
经过上面两个步骤,我们已经有了粗略的物体位姿。本步骤对位姿进行优化。
选择接近输入姿态的6个参考图像,通过CNN提取特征图,然后将特征图投影到3D空间中,并计算特征的均值和方差作为空间顶点的特征。
对于查询图像,使用同样的CNN提取特征图,将特征图投影到3D空间中,并将查询特征与参考图像特征的均值和方差连接起来。
最后在空间特征上使用3DCNN预测残差来更新输入姿态。
3. 实验分析
二、算法复现
2.1 环境搭建
2.1.1 Python环境
创建[[02_Anaconda的基本使用与在Pycharm中调用|Anaconda虚拟环境]]
1 | conda create -n gen6d python=3.7 |
安装pytorch环境
1 | conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorch |
安装依赖,打开requirements.txt,删除其中的pytorch, torchvision, cudatoolkit
1 | pip install -r requirements.txt |
2.1.2 自制数据集工具
(1)COLMAP
参考官网教程:https://colmap.github.io/install.html
安装依赖库
1 | sudo apt-get install \ |
下载COLMAP源代码
1 | git clone https://github.com/colmap/colmap |
修改CMakeLists.txt文件,添加下面的内容
1 | set(CMAKE_CUDA_ARCHITECTURES 86) |
开始编译、安装(注意一定要退出conda环境再编译安装)
1 | mkdir build |
(2)CloudCompare
方式1:snap(推荐)
安装snap
1 | sudo apt-get install snap |
安装cloudcompare
1 | snap install cloudcompare |
启动cloudcompare
1 | cloudcompare.CloudCompare |
方式2:Flatpak
安装Flatpak
1 | sudo apt install flatpak |
安装Software Flatpak plugin
1 | sudo apt install gnome-software-plugin-flatpak |
添加Flathub repository
1 | flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo |
安装CloudCompare
1 | flatpak install flathub org.cloudcompare.CloudCompare |
运行CloudCompare
1 | flatpak run org.cloudcompare.CloudCompare |
(3)安装ffmpeg
1 | sudo apt install ffmpeg |
2.2 数据集准备
2.2.1 官方数据集
(1)下载数据集
从原作者给出的链接中下载预训练模型,GenMOP数据集和processed LINEMOD数据集。
(2)组织数据集
将下载的文件按照下面的格式进行整理。
1 | Gen6D |
2.2.2 自制数据集
(1)视频录制
使用手机录制目标物体的参考视频和测试视频。注意:参考视频需要满足以下条件
- 参考视频中对象是静态的
- 参考视频中背景尽可能纹理丰富且平整,摄像角度要尽可能覆盖每个角度,以便COLMAP恢复相机姿态
(2)组织文件
将视频按照下面的路径进行组织
1 | Gen6D |
(3)将参考视频拆分为图像
1 | # 每10帧保存一张图像,最大图像边长为960 |
拆分后的视频保存在data/custom/coffeebox/images中。
(4)运行COLMAP SfM恢复相机姿态
1 | python prepare.py --action sfm --database_name custom/realsensebox --colmap /usr/local/bin/colmap |
注:<path-to-your-colmap-exe>可以通过命令which colmap来查找,一般ubuntu路径为/usr/local/bin/colmap,windows路径为E:/Programming/COLMAP-3.8-windows-cuda/COLMAP.bat
(5)手动处理点云
通过裁减对象点云来手动确定对象所在区域。例如使用CloudCompare来可视化处理COLMAP重建的点云,重建的点云位于data/custom/mouse/colmap/pointcloud.ply中。
1 | flatpak run org.cloudcompare.CloudCompare |
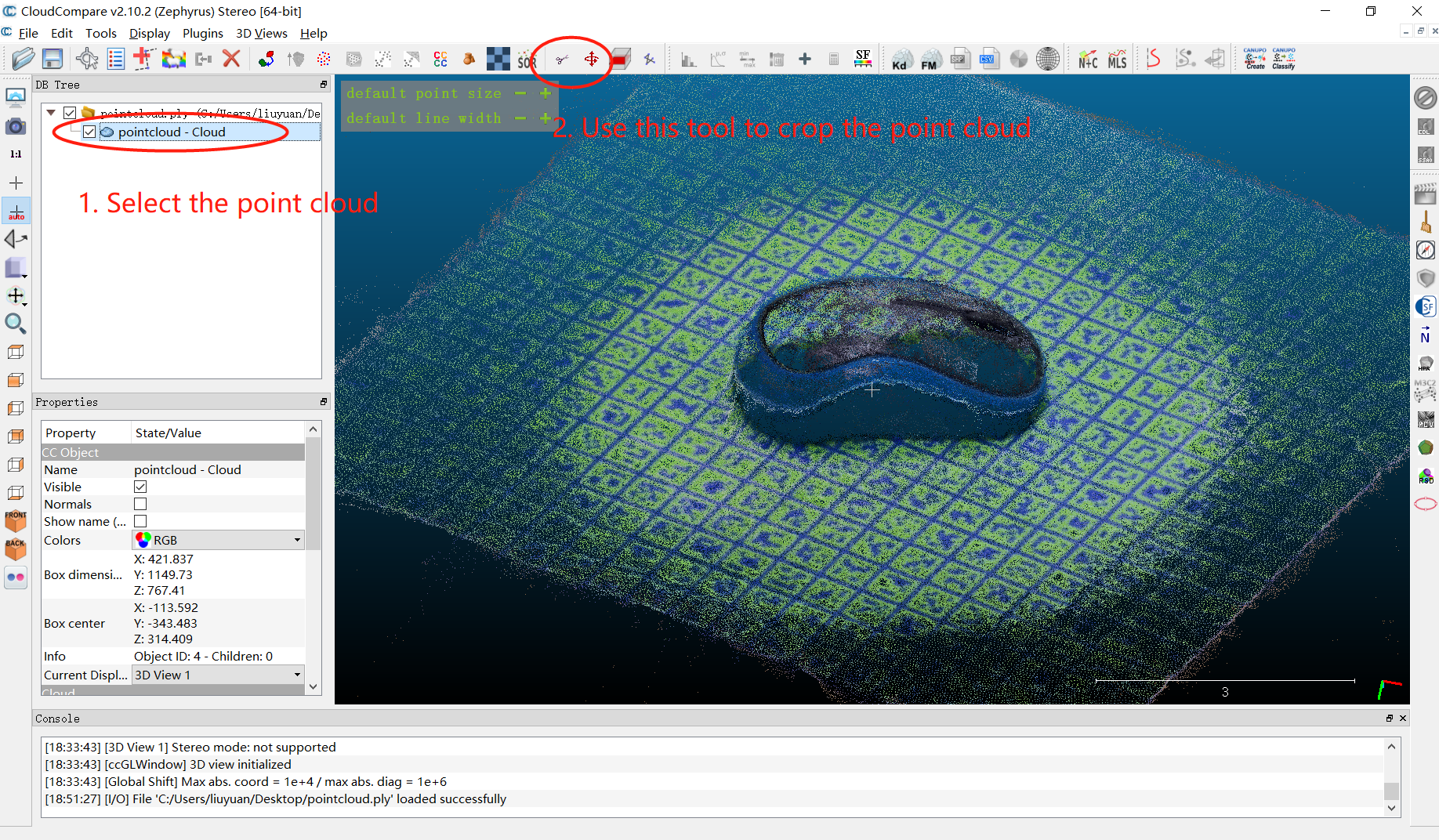
导出裁剪后的点云为data/custom/mouse/object_point_cloud.ply。
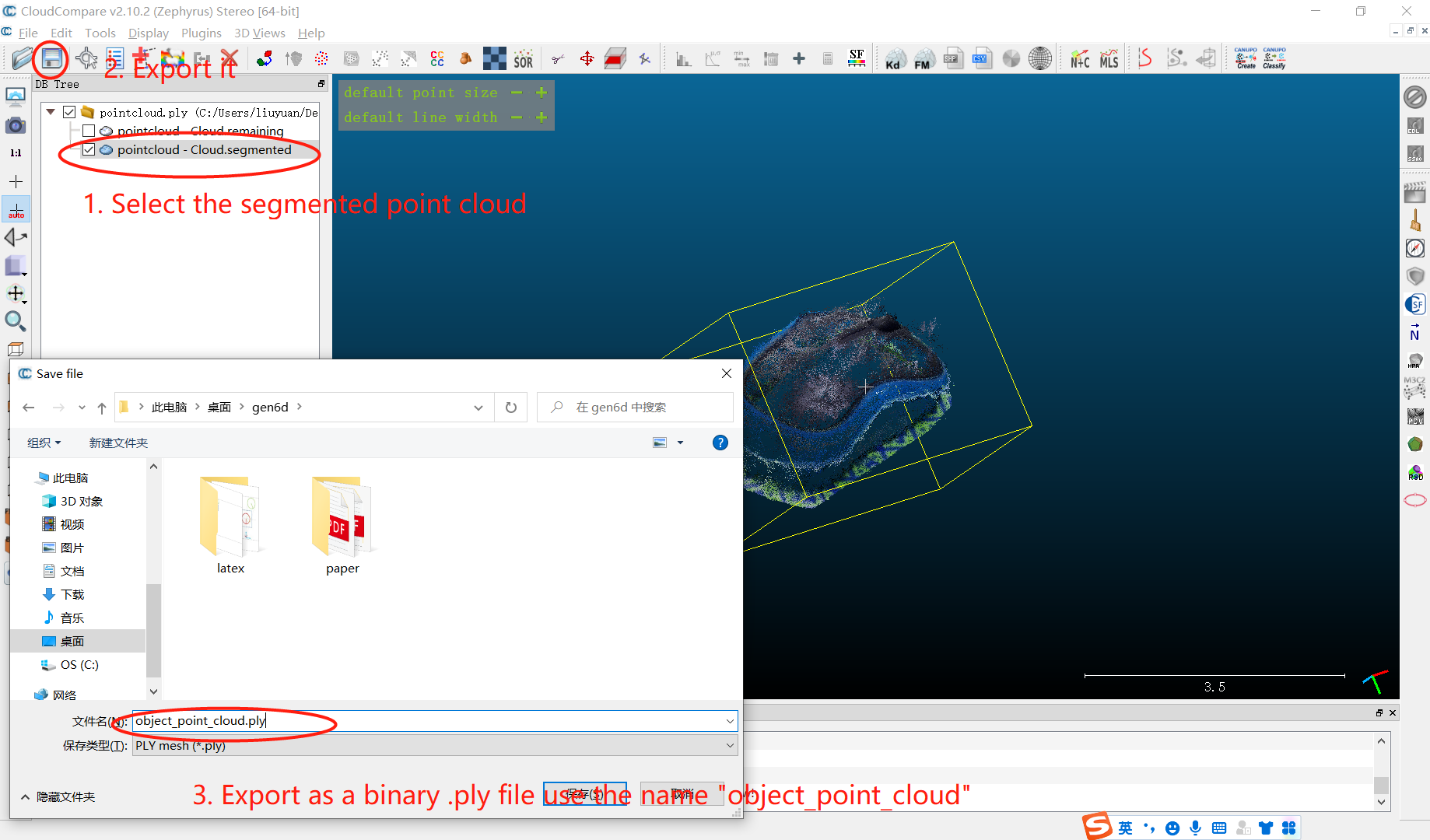
(6)手动确定对象的X轴正方向和Z轴正方向

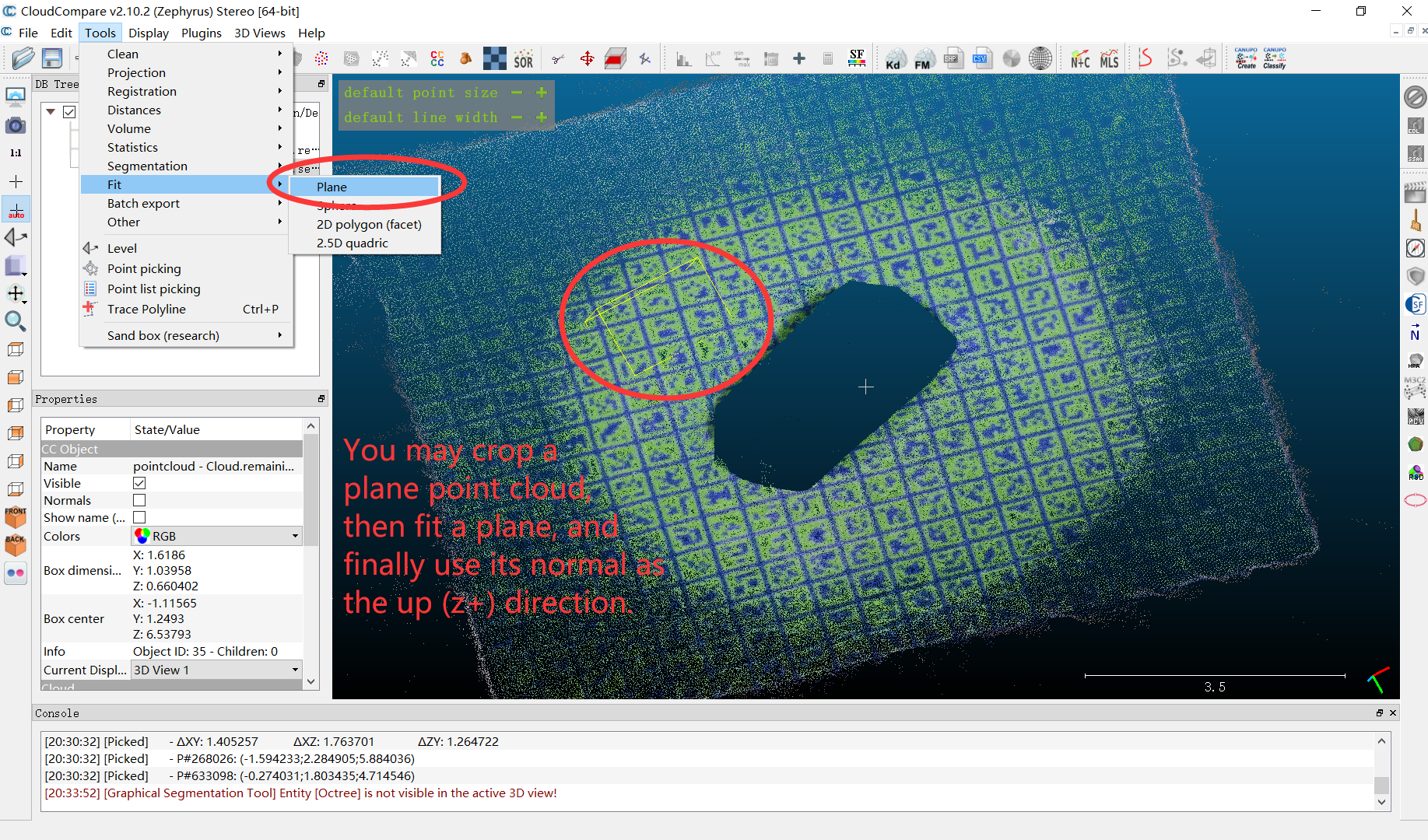
编辑一个data/custom/mouse/meta_info.txt文件来保存你的X+和Z+信息,例如
1 | 2.297052 0.350839 -0.000593 |
(7)确保您具有以下文件,这些文件由上述步骤生成
1 | Gen6D |
(8)从处理后的参考图像中预测姿势
1 | python predict.py --cfg configs/gen6d_pretrain.yaml \ |
2.3 训练与评估
在此处下载处理后的 co3d 数据 (co3d.tar.gz)、Google 扫描对象数据 (google_scanned_objects.tar.gz) 和 ShapeNet 渲染图 (shapenet.tar.gz),预训练模型(gen6d_pretrain.tar.gz)。
将文件按照下面的形式组织
1 | Gen6D |
2.3.1 训练detector
修改train_meta_info.py的第86行
1 | 'genmop_train': [f'genmop/{name}-test' for name in ['ammeter', 'coffeebox', 'realsensebox']], |
修改database.py的第109行
1 | GenMOP_ROOT = 'data/custom' |
修改database.py的第212行,修改为
1 | cameras, images, points3d = read_model(f'{GenMOP_ROOT}/{seq_name}/colmap/sparse/0') |
开始训练
1 | python train_model.py --cfg configs/detector/detector_train.yaml |
2.3.2 训练selector
1 | python train_model.py --cfg configs/selector/selector_train.yaml |
2.3.3 训练refiner
为refiner训练进行数据准备
1 | python prepare.py --action gen_val_set \ |
该命令会在data/val生成信息,该信息会被用于生成refiner的有效数据
训练refiner
1 | python train_model.py --cfg configs/refiner/refiner_train.yaml |
2.3.4 评估所有组件
1 | Evaluate on the object TFormer from the GenMOP dataset |
三、现存问题
优点
- 只需要对给定物体录制1-2分钟的视频,使用程序1-2小时添加数据集,即可实现新物体的位姿估计,不需要再训练网络
- 精度还可以
缺点
- 对于方形凸形物体识别较好,对于物体内部存在中空区域,例如圆环等物体识别效果较差
- 由于参考视频要求物体静止,因此无法录到物体底面的特征,对于物体底面识别效果较差(可考虑物体正反放置录制两次,对于同一个物体使用两个参考视频进行预测,选择置信度高的位姿)
- 当进行识别时,如果图像中不存在物体也会生成一个估计位姿(可以考虑根据置信度判断输出,或者在位姿估计前使用yolo等算法预判断物体位置)
- 当存在遮挡时位姿估计效果较差,可能会出现只框处未被遮挡的部分,或者在遮挡物体上强行进行位姿估计。
- 当要同时识别的物体很多时,对于显卡显存要求比较大,而且计算会很慢,服务器1.5s/it。如果每次只对某个特定物体进行识别,速度还可以。
 微信支付
微信支付 支付宝
支付宝