经典实例分割模型Mask RCNN
一、Mask RCNN简介
区域卷积神经网络 RCNN(Region-Convolutional Neural Networks)为两阶段目标检测器。通过对图像生成候选区域,提取特征,判别特征类别并修正候选框位置。 RCNN系列目前包含两个代表模型:Faster RCNN,Mask RCNN。
Mask R-CNN是He Kaiming大神2017年的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果。
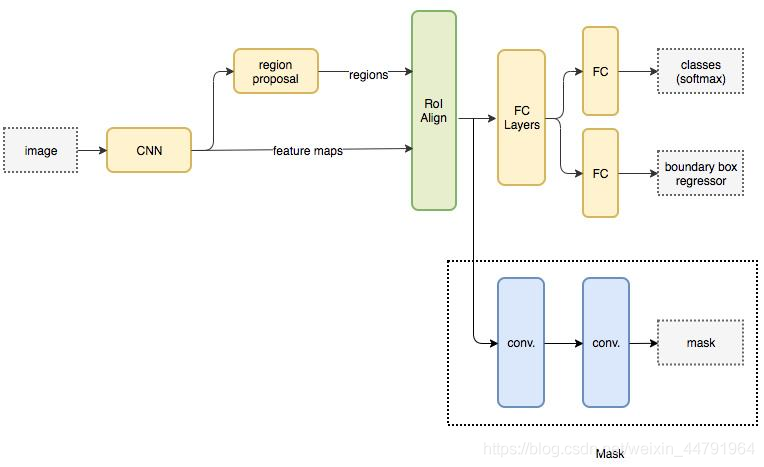
Mask-RCNN使用Resnet101作为主干特征提取网络,也就是图中的CNN部分,其对输入的图像image要求其是正方形且宽高可以整除2的6次方,不足的将会在外侧添加灰色区域。
- Resnet101主干特征提取(CNN)
一张图像image传入到 Resnet101(CNN) 之后,会对其进行特征提取,然后将图像长宽压缩两次、三次、四次、五次来构造特征金字塔,目的是为了实现特征多尺度融合。
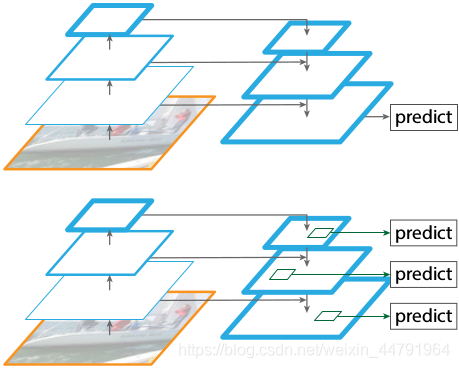
也就是下图中的左侧部分,分别得到了C2、C3、C4、C5五种特征层(五种尺寸的图像)。
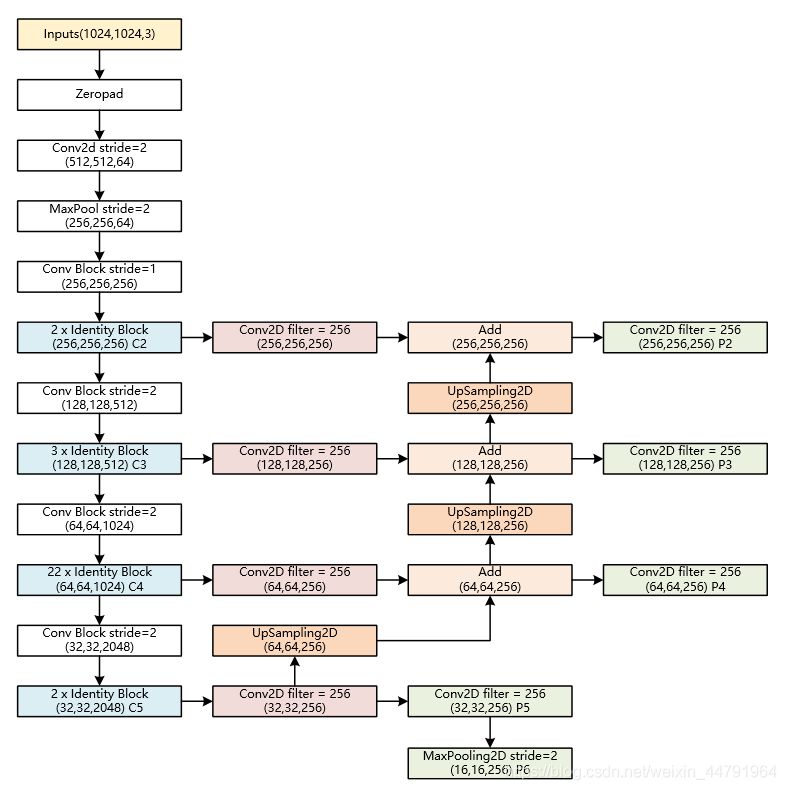
- P5:对最小的C5(32,32)图像进行二维卷积,然后再次卷积作为一个有效特征层P5(32,32)(下方绿色框)
- P6:将P5(32,32)最大池化得到有效特征层P6(16,16)。
- P4:将C5(32,32)一次卷积的结果上采样得到(64,64)图像,与C4(64,64)进行Add运算,然后再次卷积得到另一个有效特征层P4。
- P3:将C4一次卷积结果上采样,并与C3进行Add运算,然后再次卷积得到有效特征层P3。
- P2:将C3一次卷积结果上采样,并与C2进行Add运算,再次卷积得到有效特征层P2。
提取到的P2、P3、P4、P5、P6五个有效特征层,就是Resent101的输出feature maps,可以用于接下来RPN建议网络获取建议框。
- RPN区域建议网络(Region Proposal)
对有效特征层使用RPN建议网络(region proposal),获得许多建议框regions,这些建议框可能包含物体,可能没包含物体。不管包括没包括,接下来都会利用这些建议框截取P2~P5的图像,得到一个个可能存在目标的截取图像(P6不截取)。
- ROI区域对齐(ROI Align)
对于所有建议框截取图像,RoI Align都会将其调整图像尺寸为一个正方形,便于后续特征的匹配操作。
- FC Layers
根据截取出的建议框图像,利用Classifier回归模型判断截取的区域是否有物体,然后利用Classifier预测框网络对有效特征层进行解码获得最终的预测框。
- Mask语义分割网络
利用获取的最终预测框,再次在有效特征层P2~P5中截取目标图像(这次由于相当于进行了以便筛选,截取出的图像数量会少很多),将这次截取出的图像传给Mask语义分割网络进行语义分割。
二、Mask R-CNN实现过程
2.1 Resnet101-主干特征提取网络
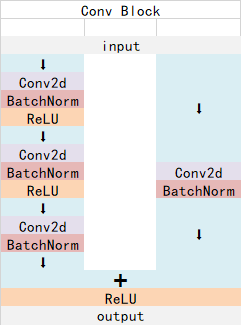
ResNet101有两个基本的块,分别是Conv Block和Identity Block。其中Conv Block的输入和输出维度不同,不能持续串联,它的作用是改变网络的维度;Identity Block的输入维度和输出维度相同,可以串联,用于加深网络。

以coco数据集中输入的shape为例,输入的shape为1024x1024,shape变化如下:
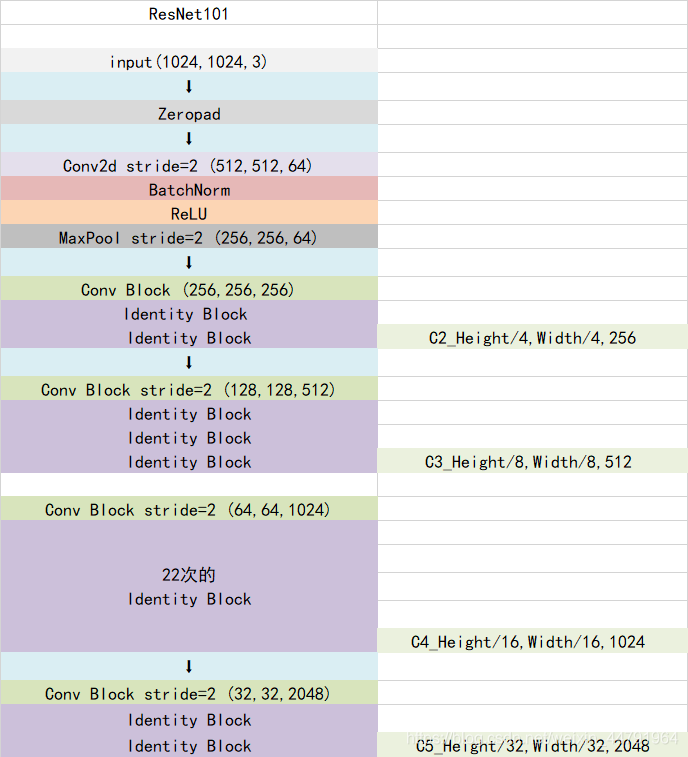
我们取出长宽压缩了两次、三次、四次、五次的结果来进行下面特征金字塔结构的构造。
相关代码:
1 | from keras.layers import ZeroPadding2D,Conv2D,MaxPooling2D,BatchNormalization,Activation,Add |
关于残差神经网络,可以参考此文章:ResNet:残差神经网络
2.2 Feature Pyramid-FPN构建特征金字塔
上文经过主干特征提取后可以得到长宽压缩了两次C2、三次C3、四次C4、五次C5的结果,用这些结果进行特征金字塔的构造,主要是为了得到P2~P6五个有效特征层。
具体过程为:
- P5:对【C5】进行一次256通道的卷积,再进行一次256通道的卷积,得到P5。
- P6:将P5进行最大池化得到P6。
- P4:将【C5一次卷积的结果】进行上采样,再与【C4进行256通道卷积的结果】的进行Add运算,再进行一次256通道的卷积,得到P4。
- P3、P2过程类似P4。
提取到的P2、P3、P4、P5、P6可以作为RPN网络的有效特征层,利用RPN建议框网络对有效特征层进行下一步的操作,对先验框进行解码获得建议框。
提取到的P2、P3、P4、P5可以作为Classifier和Mask网络的有效特征层,利用Classifier预测框网络对有效特征层进行下一步的操作,对建议框解码获得最终预测框;利用Mask语义分割网络对有效特征层进行下一步的操作,获得每一个预测框内部的语义分割结果。
具体代码
1 | # 获得Resnet里的压缩程度不同的一些层 |
2.3 构建RPN建议网络模型
RPN建议网络的模型
- 首先进行一次3x3的通道为512的卷积
- 然后分别进行一次
anchors_per_location x 2的卷积和anchors_per_location x 4的卷积。anchors_per_location x 2的卷积用于预测公共特征层上 每一个网格点上 每一个预测框内部是否包含物体。anchors_per_location x 4的卷积用于预测公共特征层上 每一个网格点上 每一个先验框的变化情况。
例如输入图片的shape是1024x1024x3时,公共特征层的shape就是256x256x256、128x128x256、64x64x256、32x32x256、16x16x256。这些公共特征层上的每一个点,映射到原始图片上就是间隔不同的网格点,每个网格默认存在3(anchors_per_location)个先验框,这些先验框有不同的大小。
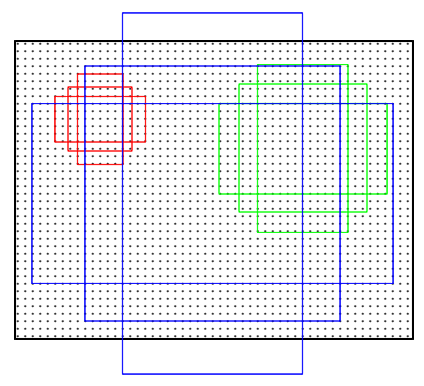
anchors_per_location x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
anchors_per_location x 2的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用anchors_per_location x 2的卷积判断是否存在物体。
实现代码如下:
1 | #------------------------------------# |
2.4 Anchors先验框的获取
先验框就是图像上的一定的区域,这些区域是人为规定好的,这些区域可能包含物体,可能不包含物体,我们网络的预测结果就会判断哪些先验框是包含物体的,然后对先验框进行调整。
在MaskRCNN中,建议框网络的预测结果就会对这些先验框进行调整,获得建议框,并判断哪些先验框是包含物体的。
本节介绍如何获得先验框。
1 | #----------------------------------------------------------# |
2.5 先验框调整获得建议框
利用ProposalLayer对先验框解码获取建议框。
1 | #------------------------------------------------------------------# |
输入参数有三个分别是rpn_class、rpn_bbox、anchors,这里的rpn_class代表所有先验框是否包含物体的置信度,rpn_bbox代表所有先验框的调整参数,anchors之前获得的所有先验框。
其中ProposalLayer的具体代码如下:
1 | #----------------------------------------------------------# |
其中利用到了下面的函数对建议框的位置和长宽进行调整
1 | #------------------------------------------------------------------# |
2.6 利用建议框对共享特征层进行截取
ROI Align层的作用就是根据建议框对不同的特征层进行截取。主要代码如下,其功能就是根据建议框的大小,判断建议框属于哪一个特征层,然后利用建议框对对应的特征层进行截取。
1 | #---------------------------------------------------------------# |
其中PyramidROIAlign函数的定义如下:
首先获取建议框的坐标、图片信息、特征层。然后根据建议框的大小,判断建议框属于哪一个特征层(较大的特征层比如256x256的,网格划分密集,每一个建议框大小比较小,以此判断)。利用循环对于P2~P5五个特征层进行截取。
1 | #----------------------------------------------------------# |
2.7 局部公用特征层到预测结果
如何利用调整后的局部特征层获得预测结果
1 | mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\ |
1 | #------------------------------------# |
2.8 建议框调整获得预测框
1 | #------------------------------------------------------------# |
我们的工作都发生在DetectionLayer四个参数分别是rpn_rois建议框、mrcnn_class建议内部物体的置信度、mrcnn_bbox建议框的调整参数、input_image_meta输入图片的基本信息。
其中DetectionLayer的定义如下:
1 | #----------------------------------------------------------# |
三、创建自己的数据集
3.1 安装labelme
打开cmd窗口,输入activate tensorflow2激活自己的anaconda环境。
然后安装labelme
1 | pip install labelme |
安装完成后直接在命令行输入labelme即可打开。
使用label进行标注,将生成的json文件和原始图像jpg,放入同一个文件夹中。
3.2 转换coco格式
1 | pip install labelme2coco |
1 | labelme2coco path/to/labelme/dir --train_split_rate 0.85 |
3.2 或者转换成mask掩码图,再数据增广,再转换coco格式
(1)labelme结果转mask掩码图
1 | import cv2 |
(2)数据增广
将rgb图和mask掩码图做同样的变换,得到数据增广的rgb和mask掩码图
1 | import imgaug.augmenters as iaa |
(3)从rgb和mask图生成coco数据
四、开始训练
运行json_to_dataset.py将标注的json图像转换为数据集。
在dataset.py中的load_shapes中添加自己的分类,同时在最后的循环中也添加自己的分类。
在train.py的ShapesConfig修改图片大小,IMAGE_MIN_DIM和IMAGE_MAX_DIM两个图片大小可以一样,NUM_CLASSES后面的数字是分的类
 微信支付
微信支付 支付宝
支付宝