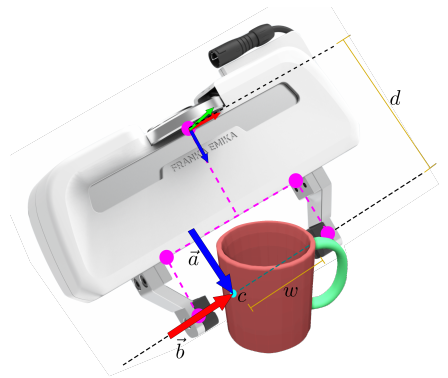
【模仿抓取】从人类演示中学习机械臂抓取
1 DemoGrasp: Few-Shot Learning for Robotic Grasping with Human Demonstration
标题:DemoGrasp: 机器人抓握的少镜头学习与人体演示
作者团队:慕尼黑工业大学
期刊会议:IROS
时间:2021
代码:
1.1 目标问题
1.1.1 现存问题
现有的位姿估计方法要么需要计算目标物体的6D位姿,要么需要学习一组抓取点。前者的方法不能很好的扩展到多个对象实例或类,后者需要大型注释数据集,并且由于其对新几何图形的泛化能力交叉而受到阻碍。
1.1.2 解决思路
通过简单简短的人类演示教机器人如何抓取物体,不需要许多带注释的图像,也不局限于特定的几何形状。
1.1.3 大致方法
首先构建一个人机交互的RGB-D图像序列。利用该序列来构建表示交互的手和对象网格。完成重建对象形状的缺失部分,并估计重建模型与场景中可见对象之间的相对变换。最后将物体和人手之间的相对姿态的先验知识以及对场景中当前物体姿态的估计转化为机器人必要的抓取指令。
1.1.4 引言总结
为什么要做这个研究:
当前的机器人抓取缺乏泛化能力,因为它们要么专注于估计物体姿态,要么学习抓取点,这需要物体的详细先验信息或大量注释。就像人手一样,机器人的抓取器和手臂的运动范围也有自然的限制,自由度也有限,这限制了它们可能的抓取姿势。虽然机器人抓取器和人手的运动模型可能有很大差异,但应该可以从人类操作中提取信息,并从中推断出目标机器人的足够抓取命令。通过有限的人类演示,机器人可以模仿人类行为,从而无缝抓取物体。
本文主要做了什么:
我们专注于这种模仿,机器人反映了人类的互动,如图1。该任务可以分为视觉感知和解释部分,其中人类教员演示先验操纵(Demo),机器人从中推断出操纵当前场景所需的抓握信息(抓握)。如果从人手到机器人抓取器有足够的映射,将任务分解为这两个阶段可以使我们的方法扩展到大量不同的抓取器。最终,这为通过自然人类演示来教授机器人铺平了道路,从而实现更高水平的自动化,尤其是在结构较少的环境中。
本文大致是如何实现的:
在从各种不同的角度向机器人演示物体(Demo)的过程中,我们的方法不断跟踪手和物体,这些手和物体被融合到截断有符号距离场(TSDF)中,用于3D重建。使用手和对象的语义分割,可以分离并进一步处理重建,以检索对象和手的完整3D表示。然后,我们利用MANO手部模型提取相关的3D手部网格,并将其与重建对象紧密对齐。在推理过程中,我们使用PPF FoldNet来预测对象是否存在,以及它从对象到相机空间的相对变换。然后,应用所估计的姿势从所估计的手网格导出最终抓握指令。
1.2 方法
总体流程:
- 在一组人类演示RGB-D图像上分割手和物体,并使用记录的深度图重建它们的形状
- 补全物体形状
- 提取手部姿态
- 估计对象的6D姿态,转换手部模型,推理抓取指令
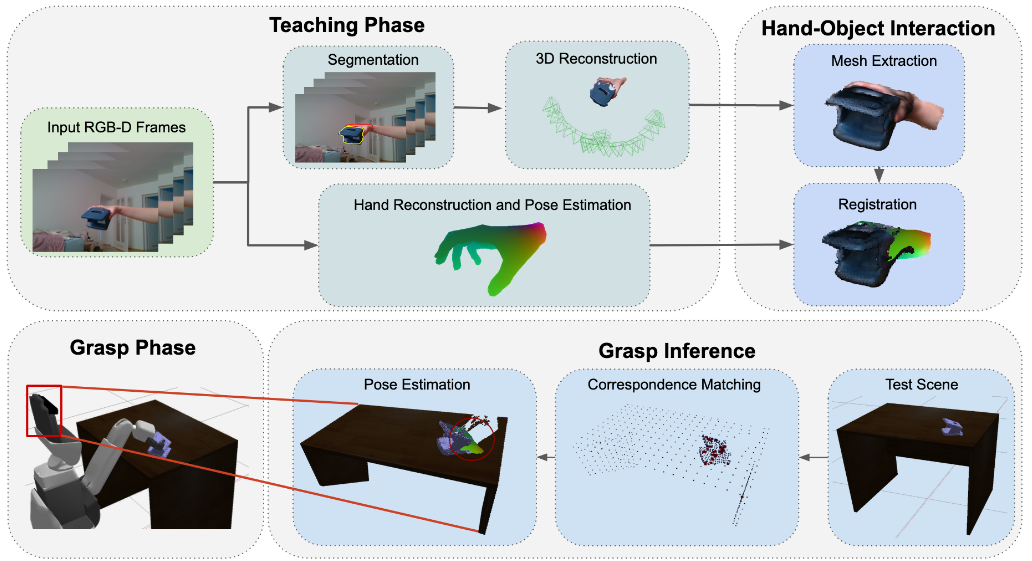
1.2.1 人-物交互的三维重建
使用MaskRCNN对手和物体进行分割,并且应用了二进制交叉熵来防止类间竞争。
利用分割后的深度图像,通过KinectFusion创建相应的TSDF体素,并通过输入帧与TSDF之间的ICP配准实现无漂移跟踪。
(因为家用物体几何形状简单,因此同时跟踪手和物体,手的结构复杂稳定了跟踪结果)
利用分割结果,通过两个单独的TSDF重建将手和物体分离开。
1.2.2 物体形状补全
由于自遮挡和部分可见性,重建的模型还不完整。
使用3D CNN直接矫正TSDF体积,然后通过行进立方体进行形状提取。
(这里使用了UNet的3D变体,输入是64x64x64的体素,输出每个体素的预测分数表示体素是否被占用。
1.2.3 手部姿态估计
从重建的手形状中估计手部参数模型。
使用MANO手部模型,将手部姿态和形状参数映射到网格中。由于手部也受到了部分遮挡,因此使用辅助接触和碰撞损失联合训练CNN进行手部网格和物体网格估计。
为了进一步改进抓握位置,使用ICP将手部网格与手部TSDF体素对齐。
1.2.4 抓取指令生成
首先检索物体姿态,然后用它来变换手部网格,并用手部模型的拇指和食指计算抓握点。
1.3 思考
- 物体的三维重建可以采用其他方式,或者结合CAD模型补全的方式,相比于使用3D CNN预测效果会更好。
- 手部姿态的提取也可以考虑采用更新的算法,例如识别手部关键点,而不是预测手部网格的方式。
- 抓取姿态生成是直接使用拇指食指作为二指抓取姿态,是否可以考虑其他方式,提高抓取的可靠性。
2 Learning to Grasp Familiar Objects Based on Experience and Objects’ Shape Affordance
标题:基于经验和物体形状的相似目标抓取
作者团队:慕尼黑工业大学
期刊会议:IEEE TRANSACTIONS ON SYSTEMS MAN CYBERNETICS-SYSTEMS
时间:2019
代码:
2.1 目标问题
2.1.1 现存问题
对于已知物体的抓取方法,物体具有抓取数据库,机器人通过估计物体姿态,然后利用国旅行假设找到合适抓取姿态,但是这些方法的缺点是不可能将所有对象的模型都放入机器人的数据库。
需要一种从以前的经验推广到新对象的模型的能力。
2.1.2 解决思路
整合人类抓握经验中的关键线索(拇指指尖和手腕的位置方向),提出了一种有效的抓握方法。
2.2 方法
2.2.1 从不完整点云上生成抓取点
在抓取时,熟悉对象上的抓取点在对象上具有相似的相对位置。
基于这个原理,使用3D SHOT形状描述符描述物体,能够精确的描述兴趣点相对于整个对象和表面的位置。具体学习抓取点的过程如下:
- 收集从部分点云中选择的兴趣点的SHOT特征、LR特征、RGB特征
- 通过计算简单的统计数据,如范围、均值、标准差、熵等,降低沿点维度的特征维度
- 将特征输入到用于对象分类的极限学习机中。
2.2.2 构建抓取模型
没看懂。
大概是建立大拇指和物体之间的坐标变换关系,然后将其转换为三指夹爪与物体之间的坐标变换。
2.2.3 腕关节约束估计
主要是解决受外在单一视角下点云被遮挡,无法精确确定手腕方向的问题。
3 R3M: A Universal Visual Representation for Robot Manipulation
标题:R3M:机器人操纵的通用视觉表示
作者团队:斯坦福大学,Meta AI
期刊会议:CoRL
时间:2022
代码:https://tinyurl.com/robotr3m
3.1 目标问题
训练机器人根据图像完成操作任务。给定一段文字,例如“将铲子放到锅里”,机器人根据视觉执行相应的动作。
(1)传统方法的局限性
传统且广泛使用的方法是使用同构数据从头开始训练端到端的模型,但是由于训练数据难以获取,限制了这种方法的泛化。而我们还有没合适的机器人数据集,最近的数据集都是由少数不同环境有限任务组成,因此泛用性受到限制。
(2)本文的突破思想
参考ImageNet等通用有效的模型,机器人领域目前还没有类似的模型出现,但是思想可以借鉴,就是使用丰富的in-the-wild data(野生数据?),也就是使用人类与环境交互的视频,这些数据庞大且多样化,包含全球各种场景与任务。
(3)本文方法简述
训练了一种机器人操纵表示方法R3M。R3M能够学习具有挑战性的任务,例如将菜放入锅中,折叠毛巾等。
3.2 方法
本文认为,机器人操作的良好表现由以下三个方面组成
- 机器人应该捕获时间动态,因为机器人在环境中要按时间顺序完成任务
- 机器人应该捕获于一相关的特征
- 机器人应该是紧凑的
(1)时间对比学习
训练编码器生成一个表示,是的时间上较近的图像之间的距离小于时间上较远的图像或来自不同视频的图像。
(2)视频语言对齐
捕获语言的特征,学习视频场景中的语义部分。
(3)正则化
降低状态空间的维度来保证克隆训练的策略符合专家状态分布。
3.3 思考
与本人方向有差别,本文更偏向于语义,视觉只是作为一个感知手段。
4 Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
标题:对抗性技能网络:来自视频的无监督机器人技能学习
作者团队:德国弗赖堡大学
期刊会议:arXiv
时间:2019
代码:http://robotskills.cs.uni-freiburg.de/
4.1 目标任务
从未标记的多视角视频中学习机器人操作任务。
(1)传统方法的局限性
现有的强化学习方法尽管有一些进展,但是这些方法都是学习每项任务的解决方案,并且依赖于手动的、面向任务设置的奖励函数,所获得的策略也是针对于特定任务的,无法转移到新任务上。
(2)本文的创新点
提出一种无监督的技能学习方法,称为对抗性技能网络ASN,通过观看视频来发现和学习可转移的技能。学习到的技能被用于RL,以便通过组合以前的技能来解决更广泛的任务。
该方法不需要帧和任务ID的对应关系,不需要任何额外的监督。
4.2 方法
Adversarial Skill Networks对抗性技能网络
我们在对抗性框架中学习技能度量空间。网络的编码部分试图最大化熵以增强通用性。鉴别器在测试时不使用,它试图最小化其预测的熵,以提高对技能的识别。最后,最大化所有技能的边际类熵会导致所有任务类的统一使用。请注意,不需要关于框架和它们所源自的任务之间关系的信息。
(没看懂)
4.3 思考
似乎可以从无标签的视频中学习任务。但是过于理论化。
5 BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
标题:BC-Z:利用机器人模仿学习实现零样本任务泛化
作者团队:谷歌、加州大学伯克利分校、斯坦福
期刊会议:CoRL
时间:2022
代码:https://sites.google.com/view/bc-z/home
5.1 目标问题
使基于视觉的机器人操作系统能推广到新任务。
为此,开发了一个交互式模仿学习系统,可以传达人物的不同信息作为条件,包括自然语言或者人类演示视频,该系统可以从演示中进行学习。并且发现学习到100个任务之后,可以执行24个未训练的任务且不需要演示。
(1)现存问题
机器人技术的一大挑战就是创造一种能够在非结构化环境中基于任意的用户命令执行大量任务。这一工作的关键挑战是泛化。机器人必须要能处理新的环境,识别和操纵以前从未见过的物体,并且理解从未被要求执行过的命令的意图。
传统的方法是在像素级进行端到端的学习,然后由足够的真实世界的数据,这些方法原则上能够使机器人在新的任务、对象、场景中进行泛化。但实际上这一目标还是遥不可及。
本文要解决的问题就是通过零样本或者少样本推广基于视觉的机器人操纵任务的问题。

5.2 数据收集
为100个预先指定的任务手机了人类演示的视频,这些视频包含了推物体、拿取放置物体等9项基本任务。
搭建一套远程操作系统,远程操作设备通过USB连接到机器人上,通过两个手持控制器遥控操作站在机器人后面,使用控制器以第三人称视角操作机器人,机器人实时响应跟随操作员演示各种任务。
5.3 方法
5.3.1 语言和视频编码
编码器以语言命令或人类视频作为输入,并生成任务。
- 如果是语言命令,使用预训练的多语言语句编码器为每个任务生成512维语言向量
- 如果是视频,使用基于ResNet18的卷积网络
5.3.2 训练策略
给定固定的任务,我们通过XYZ和轴角预测的Huber损失和抓取器角度的对数损失来训练。
开环辅助检测,如果以开环的方式运行,将采取是个行动的开环轨迹。开环预测提供了一个辅助训练目标,并可以离线检查闭环规划质量。
将状态差异作为操作,标准的模仿学习会将演示动作直接作为目标标签,而本文的专家克隆行为会导致一些小动作或抖动,因此考虑将动作定义为未来目标和下一步的差异,使用自适应算法确定手臂和夹爪的移动量。
5.3.3 网络架构
使用ResNet18作为主干,从主干最后一个平均池化层分出多个head,每个head是一个多层感知机,对末端执行器动作的一部分进行建模,具体见原文。
5.3 思考
首先提供演示视频和文字,然后手动控制机器人执行任务收集数据。似乎仍然较为繁琐。
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
标题:VIP:通过价值内隐预训练实现普遍的视觉奖励和表现
作者团队:Meta AI,宾夕法尼亚大学
期刊会议:ICLR
时间:2023
代码:https://sites.google.com/view/vip-rl
6.1 目标问题
特定任务的机器人数据的成本较高且稀缺。从大型、多样化的离线人类视频中学习已经成为获得普遍有效的途径。然而如何将这些人类视频用于通用的奖励学习仍然是一个未解决的问题。
与模拟环境中的机器人控制不同,真实世界中的机器人任务无法获得很好的环境状态信息或者定义良好的奖励函数。现有的方法学习每一项任务都需要大量的准备工作。相反,一个简单的方法来指定真实世界操作任务就是提供一个目标图像,图像捕捉环境所需要的视觉变化。然而现有的方法不能产生有效的奖励函数。
本文提出了一种隐含价值预训练方法(Value-Implicit Pre-training, VIP),一种自监督的预训练视觉表示,为机器人任务生成奖励函数。
本文的关键在于,将强化学习本身作为强化学习的预训练机制,但是由于人类视频中没有可以用于策略学习的动作信息,因此我们使用这种双价值函数,在没有动作的情况下以完全自我监督的方式进行预训练。
6.2 方法
(1)从人类视频中自我监督的价值学习
虽然人类视频不是机器人域的数据,但是它们是学习人类行动的目标条件策略的领域中的数据。因此考虑使用离线人类视频进行学习的一个合理方法是在人类的策略空间上解决目标条件的强化学习问题,提取视觉表示(本文考虑使用 KL 方法进行离线强化学习)。
由于动作不出现在这个强化学习的目标中,并且所有数据都可以用离线数据集采样,因此可以通过适当选择奖励函数来对双价值函数进行自监督。
(2)隐含的时间对比学习
当有意义的指示任务的开始和结束的两个帧在嵌入空间中接近时,初始帧和目标帧之间能够捕获长程语义时间依赖性。
(3)基于隐含价值的预训练
具体算法见原文。
6.3 代码实验
VIP 算法使用 ResNet50 作为视觉 backbone,并在 Ego4D 数据集上进行训练。
算法与 R3M 进行了比较
6.3 思考
7 Graph-Structured Visual Imitation
标题:图形结构的视觉模仿
作者团队:索尼
期刊会议:CoRL
时间:2019
代码:无
7.1 目标问题
当机器人动作使工作空间中检测到的相应视觉实体的相对空间配置与演示更好的匹配时,会得到奖励。
本文使用人类手指关键点检测器、使用合成增强进行离线训练的对象检测器、由视点变化监督的点检测器。在没有人类注释数据或机器人交互的情况下为每次演示学习多个视觉实体检测器。
7.2 方法
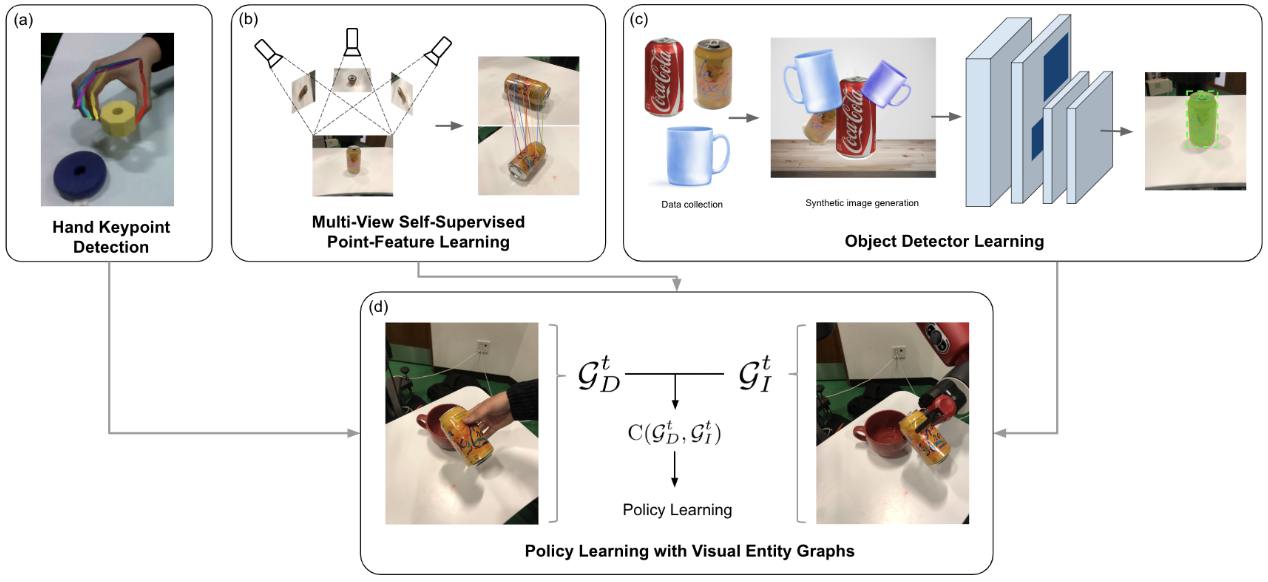
(1)检测视觉实体
人手关键点检测:使用现有的手部检测器,并使用D435i获取3D位置。将机器人平行钳口夹持器映射到演示者的拇指和食指指尖。通过在两个指尖设置距离阈值来检测抓取和释放动作。
点特征检测器:训练后,在模仿者和演示者的环境中匹配点特征,建立对应关系。
合成数据扩充:使用背景移除来提取出2D掩模,并使用合成数据增强来训练视觉检测器。
(2)动态图构造的运动显著性
(3)基于可视化实体图的策略学习
目标是当机器人从单个人类演示中模仿物体操纵任务。具体的成本代价函数参考原文。
7.3 思考
提取手部关键点映射到机器人夹爪,同时使用物体关键点检测来实现运动策略的生成。思路上不如DemoGrasp更直观。
可行的方法
- 提取演示视频中物体位姿
- 模仿执行动作
- 将当前视角下物体位姿与演示视频中每一帧位姿计算误差损失
- 根据误差实时计算末端位姿调整姿态
- 将当前帧手臂关键点加入,获取机械臂各关节应到的位姿
- 执行机械臂动作(期间加入机械臂避障与轨迹平滑)
8 Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
标题:通过观看学习:人体视频中操纵技能的物理模拟
作者团队:多伦多大学
期刊会议:IROS
时间:2021
代码:http://www.pair.toronto.edu/lbw-kp/
8.1 目标问题
通过观看学习,通过模仿指定任务的单个视频来进行策略学习的算法框架。
- 由于人类手臂与机器人手臂形态不同,我们的框架学习无监督的人-机器人的翻译来克服形态不匹配问题。
- 为了捕捉对学习状态至关重要的显著区域的细节,我们的模型采取了无监督关键点检测。检测到的关键点形成包含语义上有意义的信息的结构化表示,并可以直接用于计算奖励和策略学习。
8.2 方法
本文所提出的LbW框架由三个部分组成
- 图像到图像的翻译网络:逐帧翻译输入的人类演示视频,生成机器人演示视频
- 关键点检测器:将生成的机器人演示视频作为输入,提取每帧的关键点,形成关键点轨迹
- 策略网络:将当前的基于关键点的观察表示传递给策略网络,用于预测与环境交互的动作
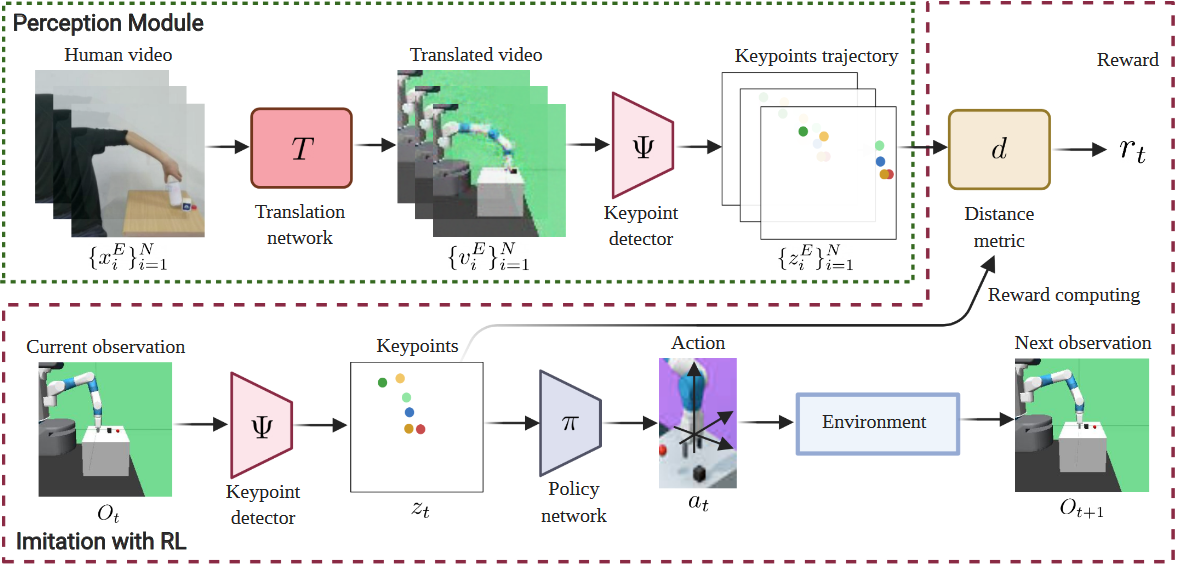
8.3 思考
与其说是模仿学习网络,不如说是一个图像翻译网络,基于CycleGAN的图像翻译,将人手演示翻译成机器人动作视频,然后提取视频中机器人的关键点轨迹,通过策略函数实现实物机器人的动作。
9 Learning Periodic Tasks from Human Demonstrations
标题:从人类演示中学习周期性任务
作者团队:卡内基梅隆大学
期刊会议:ICRA
时间:2022
代码:
9.1 目标问题
使用主动学习来优化参数,提出了一个目标最大限度的提高机器人操纵物体的运动与演示视频中物体运动之间的相似性。重点在于可变形物体和颗粒物体。(用布擦拭表面,缠绕电缆,用勺子搅拌颗粒物质等)
9.2 方法
本文提出的框架由两部分组成
- 表示学习模块:关键点检测模型从独立收集的非特定任务的人类和机器人数据中提取一致的关键点
- 姿态优化模块:将产生在检测的关键点方面与人类演示相匹配的机器人视频
9.3 思考
给定人类演示动作和手动操控机器人演示动作,机器人学习两者的相似性,然后重复演示动作使其更接近人类演示效果。
10 One-Shot Hierarchical Imitation Learning of Compound Visuomotor Tasks
标题:复合视觉运动任务的一次性层次模拟学习
作者团队:加州大学伯克利分校
期刊会议:arXiv
时间:2018
代码:https://sites.google.com/view/one-shot-hil
10.1 目标问题
真实机器人上从人类执行任务的视频中学习多阶段任务。
10.2 方法
对于每个子任务,我们提供多个人类演示和多个机器人演示(需要对象和执行的任务对应,但是不用相同的对象位置、执行速度)
(1)基元的合成:训练了一个人类相位预测器和机器人相位预测器,从人类执行视频中学习特定的机器人策略
(2)原始相位预测:学习如何分割复合任务的人类演示;何时学习策略过度到下一个。
10.3 思考
提供人的演示视频,机器人的演示视频,然后训练策略。最后利用训练的策略,提供一段人类演示视频,机器人执行对应的操作。
11 Third-Person Visual Imitation Learning via Decoupled Hierarchical Controller
标题:基于解耦层次控制器的第三人称视觉模仿学习
作者团队:MIT
期刊会议:NeurIPS
时间:2019
代码:https://pathak22.github.io/hierarchical-imitation/
11.1 目标问题
通过从第三人称视角观看人类演示视频,可以在未知场景中操纵新物体。
11.2 方法
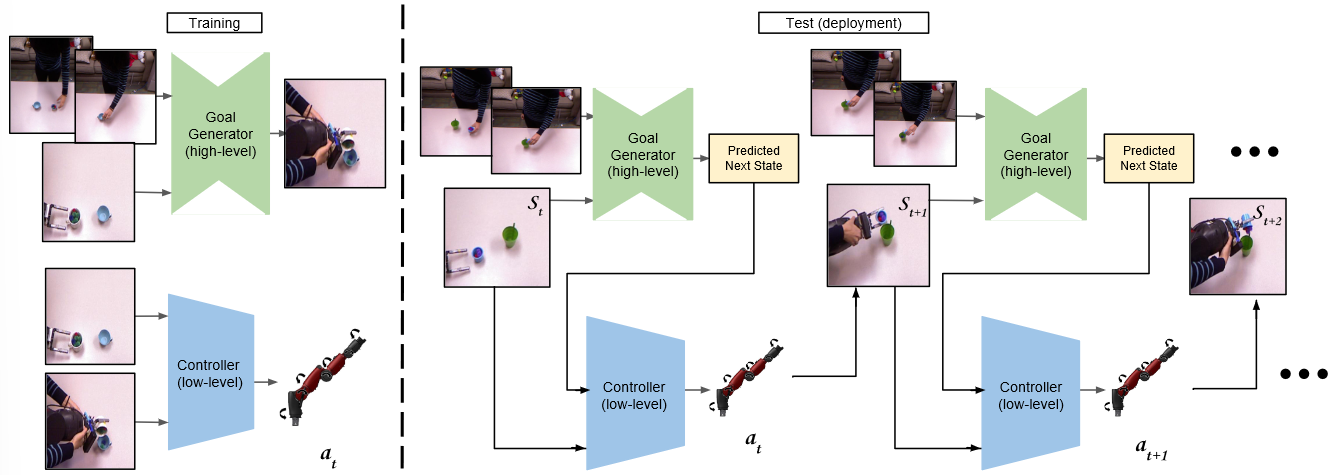
(1)目标生成器
从人类演示视频中推断像素空间中的目标,并以像素级的表示形式将其转化为机器人环境中的目标。
也是使用图像翻译的方法,将人类演示图像翻译为机器人演示图象。
(2)反向控制器
跟踪视觉目标推理模型中生成的线索,并生成机器人要执行的动作。
使用ResNet18模型。
(3)第三人称模仿
以交替方式运行目标生成器和反向控制器。目标生成器生成子目标,低级控制器生成机器人关节角度,直到人类演示结束。
11.3 思考
还是使用图像翻译的思路,把人手操作图像翻译成机械臂操作图像,再由控制器生成机器人关节角度。
12 You Only Demonstrate Once: Category-Level Manipulation from Single Visual Demonstration
标题:Yodo:单一视觉演示的类别级操作
作者团队:罗格斯大学
期刊会议:RSS
时间:2022
代码:
12.1 目标问题
由于最近的跨对象类别级操作虽然有很好的结果,但通常需要昂贵的真实数据收集和为每个对象类别和任务手动指定语义关键点。并且粗略的关键点预测和忽略中间动作序列阻止了在抓取和防止之外的复杂任务的应用。
本工作提出了一种新的操作框架。该框架利用了无模型6D跟踪技术,解析单个演示视频中的类别级任务轨迹,整个执行过程被分解为远程、无碰撞运动和最后一英寸操作三个步骤。
12.2 方法
对于每个演示视频帧,通过无模型6D位姿估计跟踪目标位姿,对象位姿在容器的坐标系中表示,这样允许泛化到新的场景。
(1)类别级表示的离线学习
建立了一个9D物体表示方法,6D位姿+3D缩放
(2)无模型的物体6D跟踪
物体运动跟踪要实现两个目的
- 演示阶段,解析录制的视频,提取容器坐标系中被操纵的对象的6D运动轨迹
- 在线执行期间,为闭环控制器提供视觉反馈
(3)类别级行为克隆作为最后一步策略
产生密集的离散轨迹,以便机器人能沿轨迹到达下一个目标
(4)基于局部注意的动态类别级框架
自动动态地规范坐标系原点。
(5)抓取物体并使其沿关键点移动
常规的抓取方法
12.3 思考
将目标位姿表示为相对于另一个物体的相对位姿,这样有助于场景的泛化。
整体思想就是使用6D位姿估计获得目标的运动轨迹,然后重复这条轨迹。
 微信支付
微信支付 支付宝
支付宝