【论文笔记】基于强化学习的机器人动作模仿
1 Reinforcement Learning with Videos: Combining Offline Observations with Interaction
标题:视频强化学习:将离线观察与互动相结合
作者团队:宾夕法尼亚大学
期刊会议:CoRL
时间:2020
代码:https://github.com/kschmeckpeper/rl_with_videos
1.1 目标问题
应用强化学习使机器人学习技能,通常需要大量的机器人在线数据,但是机器人的数据收集非常麻烦困难,难以获得足够多的数据。
人类视频广泛且多样,因此考虑从人类经验中进行强化学习。但因为人类视频没有动作的标注,并且人类视频和机器人相机图像,具有巨大的图像差异和视角差异。具体问题如下:
- 机器人必须能通过观察来更新策略,不需要任何的行动或者奖励;
- 人手与末端执行器视觉差异较大,自由度也不同,因此需要考虑动作空间、形态、视角、环境差异带来的变化;
为了解决这些问题,本文提出了视频强化学习框架(Reinforcement Learning with Videos,RLV),使用人类数据经验和机器人数据学习策略和价值函数。
1.2 方法
(1)问题定义
该论文将问题公式化为马尔可夫决策过程 MDP,定义成元组 $(S_{int},A_{int},P,R)$,其中 $S_{int}$ 是状态空间,$A_{int}$ 是动作空间,$P$ 是环境的动力学,$R$ 是奖励函数。
机器人首先被提供了人类的观测 ${(s_{obs},s_{int}')_{1:t}}$,这些观察被建模成另一组马尔可夫决策链,其具有不同的状态和动作空间,但是两者的动力学和奖励函数是相同的。
(2)方法概述
该论文所提出的方法如下图所示,包含两个重放池,一个是无动作的观测数据 $(s_{obs},s_{obs}‘)\in D_{obj}$,另一个是包含动作条件的交互数据 $(s_{int},a_{int},s_{int}’,r_{int})\in D_{int}$,交互数据在训练期间会更新,而观测数据仅仅是初始的观测数据集。
重放池 (reply pool):存储了智能体过去经历过的(状态,动作,奖励,新状态)的数据结构,通过采样这个池中的数据进行训练,可以从过去的经验中学习更多的规律,提高决策能力。
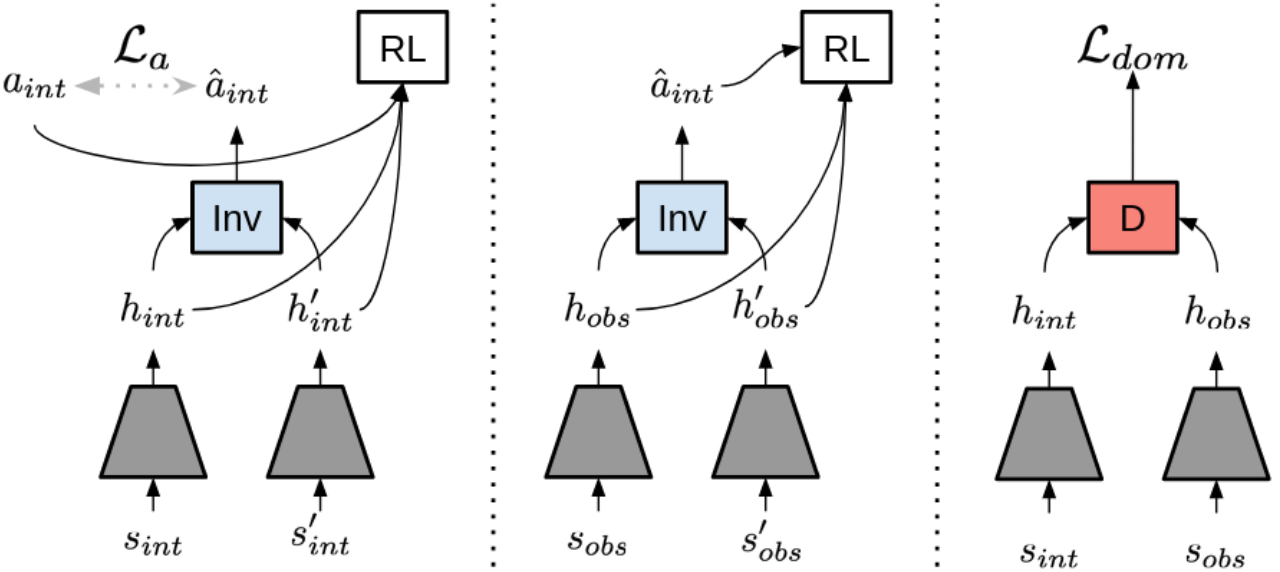
- 左图:从动作条件重放池中采样数据 $(s_{int},a_{int},s_{int}‘,r_{int})$,将观测状态分别编码成特征 $h_{int},h_{int}’$,训练一个可逆的模型,来从特征中预测动作 $a_{int}$。
- 中图:将这个可逆模型用于根据观测状态特征 $h_{obs},h_{obs}'$,预测离线视频中的缺失的机器人动作 $\hat a_{int}$,将轨迹中最后一步设置为很大的奖励,前面其它步骤都设置为很小的奖励。
- 右图:使用 adversarial domain confusion(ADS)来对齐特征,最后使用离线策略强化学习算法,对于数据 $((h_{int},h_{obs}),(a_{int},\hat a_{int}),(h_{int}‘,h_{obs}’),(r_{int},\hat r_{obs}))$ 进行训练。
Adversarial Domain Confusion (ADC):通过最小化源域和目标域之间的特征分布距离来实现跨域的迁移学习。
(3)动作预测
本文通过监督学习训练了一个参数为 $\theta$ 的逆模型,根据一对不变的特征编码 $(h,h’)$ 计算机器人动作。由于机器人与人类视频环境相同,我们应该能够预测任一马尔可夫决策过程的数据的操作。
损失使用预测动作 $\hat a_{int}=f_{inv}(h_{int},h_{int}';\theta)$ 和真实动作的均方误差 $a_{int}$:
$$
L_a(a_{int},h_{int},h_{int}‘,\theta)=||a_{int}-f_{inv}(h_{int},h_{int}’;\theta)||^2
$$
本文使用逆模型预测人手视频中的动作数据,并用它们来训练强化学习算法。
(4)奖励生成
由于强化学习使用观测数据的一个障碍就是缺乏奖励,虽然可以通过上面训练的逆模型预测奖励和动作,但实际上效果可能不会很好。
本文使用了替代方案,将观测数据轨迹的最后一个时间步长分配一个大的恒定奖励,之前的每一个时间步长分配一个小的恒定奖励。
这种方式目的是保证观测数据在轨迹结束时达到目标状态。至于其中的不准确之处,可以通过机器人收集的交互数据训练来消除。
(5)域自适应
要使用观测数据 $(s_{obs},s_{obs})'$,需要将其映射到一个不变的量 $h$。
为了实现这个目的,本文训练了一种特征编码器 $f_{enc}$,来从观测状态 $s$ 中学习编码表示 $h=f_{enc}(s;\psi)$,这种编码器应该包含所有相关的信息,并对与观测的域来说是不变的。
本文还训练了一个鉴别器,用于区分观测数据中提取的特征 $h_{obs}$ 和机器人交互数据中提取的特征 $h_{int}$。
将特征编码器和鉴别器使用对抗性学习方法进行训练,过程中编码器试图最小化鉴别器对编码特征的域的正确分类能力,鉴别器试图最大化分类能力。
最终获得的编码器就是我们需要的,将观测数据和机器人交互数据映射到不变量 $h$ 的编码器。
(6)联合优化
将领域自适应损失和逆模型的损失进行联合优化。
2 Learning Generalizable Robotic Reward Functions from “In-The-Wild” Human Videos
标题:从“野外”人类视频中学习可推广的机器人奖励函数
作者团队:斯坦福大学
期刊会议:Robotics: Science and Systems (RSS)
时间:2020
代码:https://sites.google.com/view/dvd-human-videos
2.1 目标问题
要实现通用型机器人完成各类任务,关键是机器人能够知道任务成功和奖励的能力,该奖励函数还必须能够在不同环境、任务、对象中推广。
由于收集大规模机器人交互数据是一件十分复杂困难的问题,而人类视频中则包含了大量的不同环境中的任务信息。
本文提出了一种不可知域视频鉴别器(Domain-agnostic Video Discriminator, DVD),通过训练鉴别器来分类两个视频是否执行相同的任务学习多任务奖励函数。并通过少量的机器人训练数据学习人类视频的广泛数据集进行推广。
要解决的问题:
- 人类的 wild data 和机器人的观测空间有着巨大的域变换,不管是 agent 的形态、还是场景的外观。
- 人类的动作空间和机器人的动作空间不同,可能不能很好的实现动作的映射
- 人类视频很多情况下是低质量的、有噪声的,还有着复杂的背景或视角
解决思路:
- 训练一个分类器预测两个视频是否完成的是同一个任务,也就是不可知域视频鉴别器(DVD)
- 训练完成后,DVD 能够将人类视频作为演示,机器人的行为作为另一个视频,输出一个分数,衡量任务成功的奖励。
2.2 方法
(1)Domain-Agnostic Video Discriminators
- 一个预训练视频编码器将视频 $d_i$ 编码为特征 $h_i$
- 一个全连接神经网络,预测两个视频是否完成同样的任务
- 损失函数设置见原文
- 奖励函数通过训练分类器来获得
本文的关键是训练一个分类器来学习 $R_\theta$,该分类器两个视频作为输入,判断两个视频是否属于同一个任务。视频可以来自于人类数据集或机器人数据集。
首先对视频进行采样,设两个视频为 $d_i$ 和 $d_j$,采样一批视频 $(d_i,d_i’,d_j)$ 其中 $d_i$ 和 $d_i’$ 是完成相同的任务,$d_j$ 是完成不同的个任务,最小化平均交叉熵损失训练 $R_\theta$,损失函数见原文,最终得到奖励函数如下:
$$
R_\theta(d_i,d_j)=f_{sin}(f_{enc}(d_i),f_{enc}(d_j);\theta)
$$
其中 $h=f_{enc}$ 是一个预训练的视频编码器,$f_{sin}(h_i,h_j;\theta)$ 是一个参数为 $\theta$ 的全连接神经网络,用来预测两个视频编码特征 $h_i,h_j$ 是否完成同样的任务。
(2)使用 DVD 执行任务
使用视觉模型预测控制(Visual Model Predictive Control, VMPC)实现。
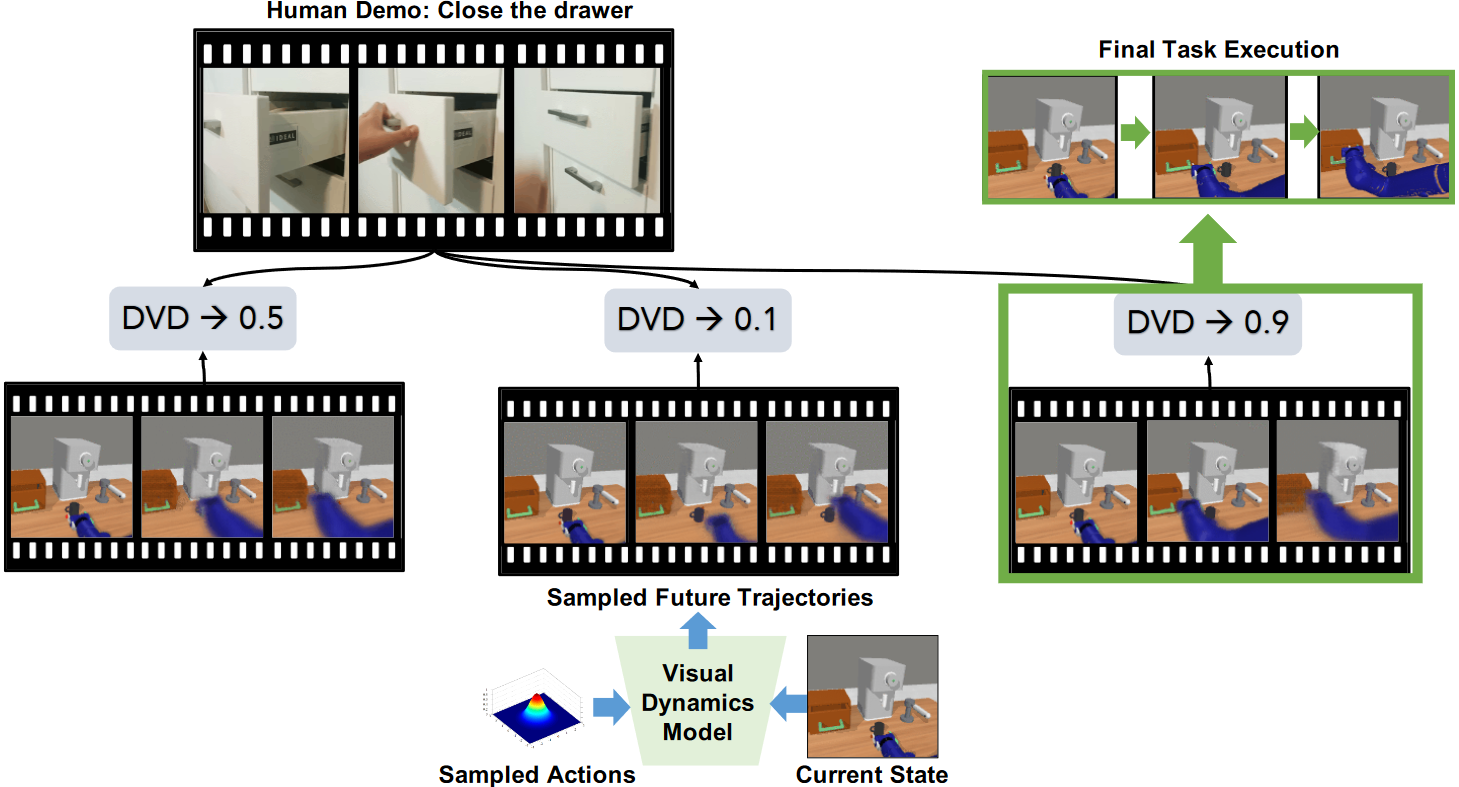
- 使用 SV2P 模型训练动作条件视频预测模型 $\rho$
- 使用交叉熵和该动作模型 $\rho$ 选择与人类演示最相似的动作
- 对输入图像,从动作分布中采样多个动作序列,并使用动作模型 $\rho$ 预测相应的未来轨迹
- 将每个预测轨迹和人类演示视频,输入DVD,得到任务相似性分数
- 执行与演示图象具有最高相似性的动作轨迹
3 PLAS: Latent Action Space for Offline Reinforcement Learning
标题:PLAS:离线强化学习的潜在行动空间
作者团队:卡耐基梅隆大学
期刊会议:CoRL
时间:2021
代码: https://github.com/sfujim/BCQ
3.1 目标问题
离线强化学习可以从固定的数据集中学习策略。
在机器人中,数据收集十分麻烦且有一定的危险性,现有的方法从离线数据集中进行学习,性能十分受限。
本文提出了潜在动作空间中的策略(Policy in the Latent Action Space, PLAS)。
3.2 方法
(0)原理基础-离线 RL
给定一个固定的离线数据集 $D={(s_t,a_t,r_t,s_{t+1})_i}$,难点在于该数据集没有覆盖马尔科夫决策过程 MDP 的整个状态空间和动作空间。
离线 RL 目的就是学习能使奖励最大化的策略,而策略受到我们对马尔可夫决策过程的了解,马尔可夫决策过程则是从有限的数据集中推理得到的。
但如果考虑离线 RL 的目标是最大化 MDP 在有限数据集下的累计回报,也能作为近似替代。并且在近似 Q 函数的时候会存在推理误差,
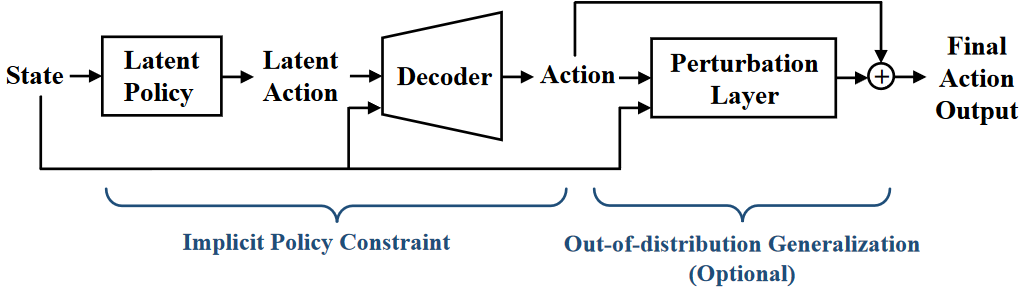
给定一个状态,潜在策略输出一个潜在动作,使用解码器将其解码为动作空间输出。(可以添加扰动层来增加泛化能力)
(1)潜在动作空间中的策略(Policy in Latent Action Space, PLAS)
给定离线数据集,本文使用条件变分自动编码器(Conditional Variational Autoencoder, CVAE)对策略进行建模。为了使策略约束在数据集的范围内,考虑使用确定性策略,从状态映射到潜在动作,再用解码器得到实际动作。
(2)泛化
潜在策略再数据集范围内能够提供约束,但是在训练的时候,本文允许了从分布外的行为的发生,即添加了一个扰动层,设置了一个超参数限制扰动层的动作输出残差。
当然,如果数据集再状态-动作空间中有着非常高的覆盖率,那么这个扰动层就是不必要的。
4 Demonstration-Guided Reinforcement Learning with Efficient Exploration for Task Automation of Surgical Robot
标题:演示引导强化学习与手术机器人任务自动化的高效探索
作者团队:香港中文大学(刘云辉团队)
期刊会议:ICRA
时间:2023
代码:https://github.com/med-air/DEX
4.1 目标问题
虽然基于强化学习的方法为手术自动化提供了可能的方案,但是通常需要大量收集数据才能进行学习。因此本文目的是提高从演示中探索学习的效率,有效地利用专家演示数据。
具体而言,目前的问题如下:
- 使用强化学习,如果不给出演示数据而仅通过探索学习,需要收集大量的数据来解决任务;
- 使用演示数据的方法,例如赋予演示数据相对于机器人探索数据更高的优先级,效率仍然低下,设置额外奖励函数的方法不仅只能针对特定环境,且容易引起局部最优;
- 使用 actor-critic 框架,通过正则化 actor 损失来衡量机器人与专家之间的行为差异,但是这种方式效率较低(尤其在初期机器人与演示差距较大情况下),且没有考虑 critic 的正则化,容易导致高估问题。
本文贡献:
- 提出一种 actor-critic 框架,降低 critic 的高估问题,提高强化学习过程中类似专家的行动进行探索。
- 使用非参数引导传播,实现未观测状态的探索
- 在 SurRoL 手术机器人上实验验证,效果优秀,同时部署在 dVRK 上,同样表示出强大的潜力。
dVRK(da Vinci Research Kit,达芬奇手术机器人系统)
4.2 方法
DEX(Demonstration-guided EXploration),演示引导探索。
(0)问题定义
将手术机器人动作学习考虑为一个 off-policy 的智能体,在由马尔可夫决策过程构建的环境中进行交互。
off-policy,指智能体不使用当前的策略来决定行动,而是使用不同的策略来生成行为数据,从过去的经历中学到最优的行为决策方法。
在 $t$ 时刻,机器人根据当前状态 $s_t$ 以及确定性策略 $\pi$ 执行行动,环境用 $r_t=r(s_t,a_t)$ 奖励智能体,然后状态转移 $s_{t+1}$。
循环此过程,每次智能体将经验 $(s+t,a_t,r_t,s_{t+1})$ 存入重放缓冲区 $D_A$。
同时设置一个演示缓冲区 $D_E$,用于存放专家策略 $\pi$ 经验。
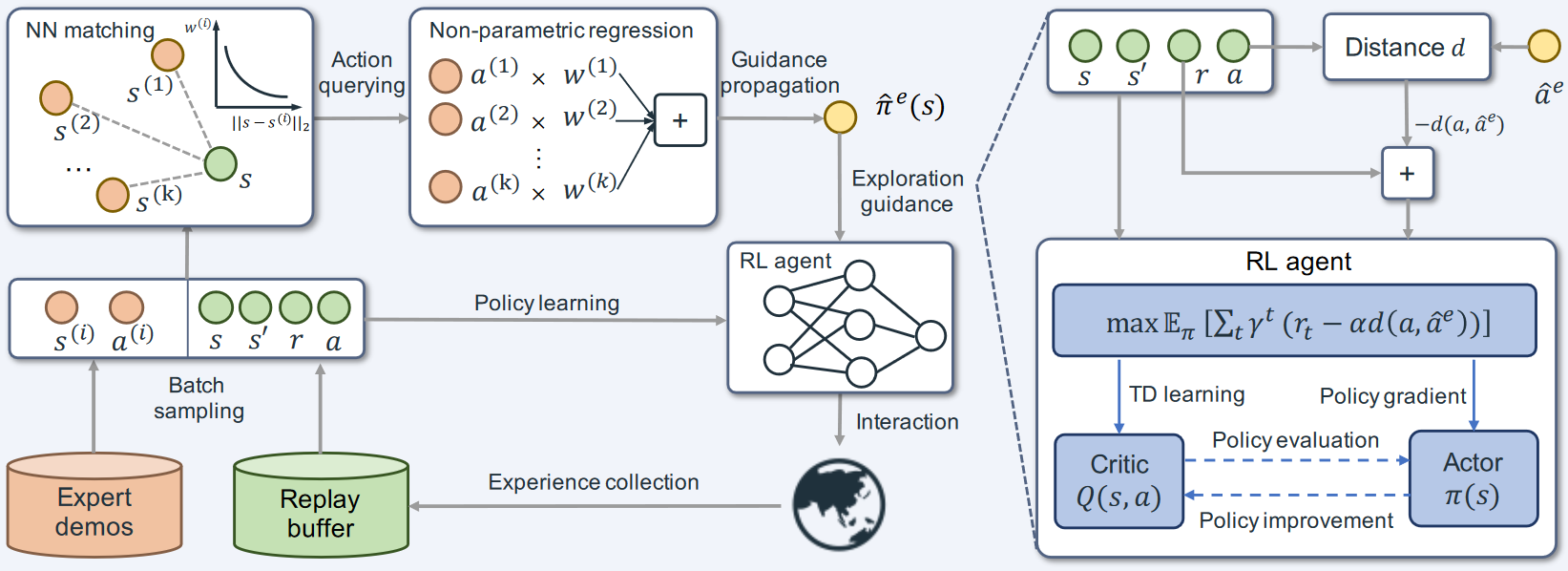
如图,该方法由两部分组成:
- 基于 actor-critic 的策略学习模块(右下角),用于从演示数据中指导探索;
- 基于最近邻匹配和局部加权回归的非参数模块(左上角),用于将与当前状态相差过大的演示传播到为当前状态。
(1)专家引导的 actor-critic 框架
现有的 actor-critic 方法通过最大化预期回报来学习最优策略,但是如果 Q 值估计不准确,会阻碍探索。本文通过利用智能体和专家策略之间的动作差距来增强环境奖励。
$$
\max_{\pi}\mathbb{E}{\pi}\left[\sum{t=0}^{\infty}\gamma^{t}(r_{t}-\alpha d(a_{t},a_{t}^{e}))\right],a_{t}^{e}:=\pi^{e}(s_{t}),
$$
其中 $\alpha$ 是探索系数,$d()$ 衡量智能体动作和专家动作之间的相似性距离度量。
基于此奖励,本文设计了正则化 Q 函数(critic),并最小化动作价值和状态价值的差距。
(2)有限演示情况下的引导的传播
智能体在初始学习阶段很容易探索演示未覆盖的区域,无法实现监督 actor 探索。
常规的解决思路有行为克隆,但是当状态相差较大时,策略与专家行动仍会有较大的不同。因此本文使用非参数回归模型,从有限的演示中将经验传播实现更稳定的引导。
首先从演示缓冲区采样一小批状态和动作,然后给定一个当前状态,在一小批状态中搜索,利用 k 近邻方法找到最接近的状态,然后使用指数和函数的局部加权回归方法近似专家策略。
$$
\hat{\pi}^e(s)=\frac{\sum_{i=1}^k\exp\left(-|s-s^{(i)}|2\right)\cdot a^{(i)}}{\sum{i=1}^k\exp\left(-|s-s^{(i)}|_2)\right)}.
$$
5 Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics
标题:剩余技能策略:学习基于技能的适应性行动空间,用于机器人强化学习
作者团队:昆士兰科技大学
期刊会议:CoRL
时间:2022
代码:https://krishanrana.github.io/reskill
5.1 目标问题
基于技能的学习已经成为加速机器人学习的方法,技能从专家演示中提取,是短序列的单步操作(平移、抓取、抬起等动作),这些技能嵌入到潜在空间中,构成上层 RL 策略的行动空间。但是这种方式存在一些问题:
- 对所有技能进行随机抽样探索,效率极低,因为其中只有一小部分技能与当前执行的任务相关,并且这些相关的技能通常不会聚集在技能空间的同一邻域内。
- 该方法假设技能是最优的,并且下层的任务来自于技能空间的相同分布,因此学习的通用性和变化适应性有限,例如从移动方块中学习技能,则无法应对障碍物、物体变化、不同摩擦等情况。
为解决上述问题,本文提出了以下创新方法,称为残差技能策略(Residual Skill Policies,ReSkill):
- 状态条件技能先验:对相关技能进行采样来引导探索
- 底层残差策略:通过对技能进行细粒度的技能适应,实现任务变化的适应
5.2 方法
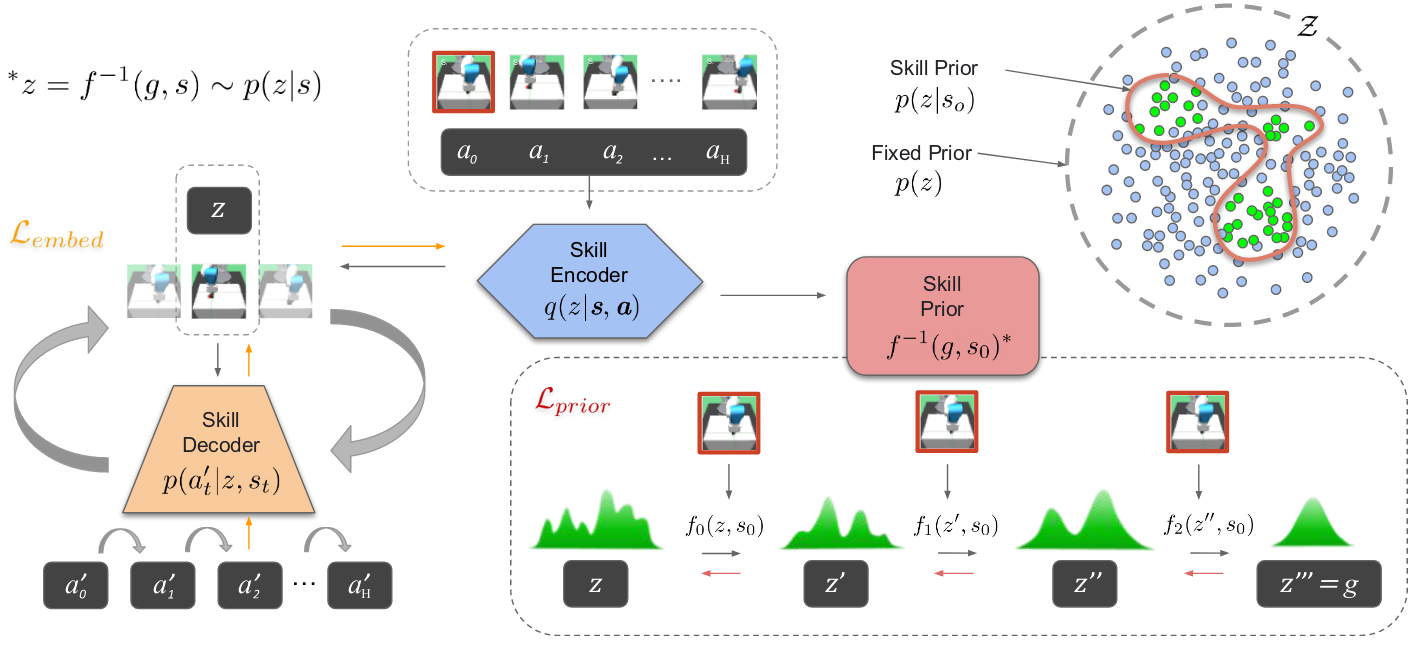
总的来说,该方法将经典控制器产生的演示轨迹分解为与任务无关的技能,并将其嵌入到连续到技能空间中,利用技能空间实现真正的通用学习,上层智能体能够从技能空间中访问但不动作,降低了对数据集详细程度的要求。
- 从现有控制器中提取技能
- 学习技能嵌入和先验技能
- 训练一个分层强化学习策略,在技能空间中使用底层残差适应性策略。
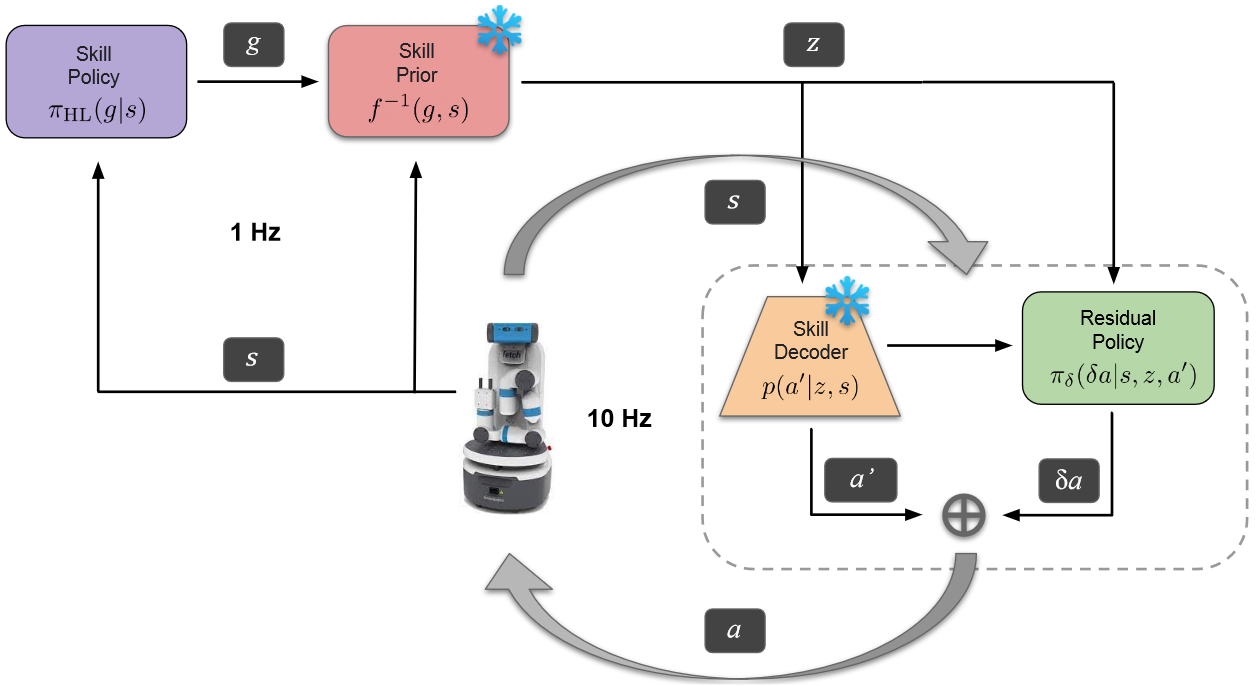
(1)数据收集
本文通过手动控制收集演示数据(基本操作任务,如推物体、抓物体),虽然任务简单,但轨迹包含复杂的技能,可以重新组合解决复杂的任务。
轨迹是由 state-action 成对组成的,本文从中随机切片 $H$ 长度的片段进行无监督技能提取,利用提取的动作 a 和状态 s 学习下一小节中的 state-action。
其中状态 s 包括关节角度、关节速度、夹具位置、物体位置,动作是连续的 4D 向量,包括末端位置和速度。
(2)学习强化学习的状态条件技能空间
- 将提取的技能嵌入到潜在空间中:使用变分自动编码器 VAE 将技能 $a$ 嵌入到潜在空间中,VAE 包括编码器和解码器,编码器将完整的 state-action 序列编码为 $z$,解码器根据当前状态 $s_t$ 和技能编码 $z$ 重建动作。
- 在探索过程中采样的技能状态条件先验:学习潜在技能空间上的条件概率密度。传统的高斯密度不能处理多模态信息,本文使用 real NVP 方法,实值非体积保留变换。学习从 $Z\times S->G$ 的映射,该映射就可以从简单分布 G 变换到技能空间 Z,因此 f 就是技能先验。
变分自编码器,是一种深度生成模型
传统:传统的自编码器包括编码器和解码器两部分,经过反复训练,输入数据被编码成一个编码向量,编码向量的每一个维度表示学习到的数据的特征,解码器尝试从编码向量中解码原始输入
缺陷:传统的方法,使用单个值表示输入在某个潜在特征的表现。但实际上,将潜在特征表示为可能的取值范围会更合理。
改进:因此变分自编码器就是使用取值的概率分布,代替原来的单值表示特征。
优势:每个潜在特征表示为概率分布,解码时从潜在状态分布中随机采样,生成一个编码向量作为解码器的输入。实现了连续且平滑的潜在空间表示(潜在空间中彼此相邻的值重构出的结果相似)
参考理解:https://zhuanlan.zhihu.com/p/64485020
(3)状态条件技能空间中的强化学习
一旦训练完成,解码器和技能先验权重就会被冻结,并合并到 RL 框架中。高级强化学习策略 $\pi$ 是一个神经网络,将状态映射到技能先验变化中的向量 g,在转换为潜在技能 Z。
然后解码器根据技能范围 H 的当前状态顺序重构动作。同时有一个底层残差策略,调整解码后的技能。
5.3 总结
该方法是一种基于技能的强化学习方法。
- 数据收集:使用最基本的控制器生成一些基本任务轨迹(移动、抓取),然后将这些轨迹分割成固定长度的序列,每一小段包括动作和对应的状态。
- 学习技能空间,使用变分自编码器将技能编码到潜在空间中;使用realNVP将技能潜在空间+机器人状态空间映射到简单分布空间(高斯分布),这样可以直接根据状态采样技能,称为技能先验。
- 强化学习:使用一个高层策略网络,根据当前的状态生成一个向量,根据技能先验(与当前状态有关的技能)中选择一个技能,利用技能解码器解码成机器人动作。
6 Watch and Match: Supercharging Imitation with Regularized Optimal Transport
标题:观看与匹配:通过正则化最优传输增强模仿
作者团队:纽约大学
期刊会议:CoRL
时间:2022
代码:https://rot-robot.github.io/
6.1 目标问题
目前模仿学习通常使用逆强化学习,给出演示的情况下,交替推理奖励函数和策略。但是这种方式需要大量的在线交互来解决复杂的控制问题。
本文提出了正则化最佳传输(Regularized Optimal Transport,ROT)方法,即使只有少量的演示,也能自适应的匹配轨迹奖励与行为克隆,加速模仿。
基于最佳传输的模仿学习(Optimal Transport,OT):模仿学习实在给定专家策略或轨迹的情况下学习行为行为策略 $\pi^b$,逆强化学习根据专家轨迹 $T^e$ 推断奖励函数 $r^e$,然后利用奖励优化策略来得到行为策略 $\pi^b$。为了计算 $r^e$,基于 OT 的逆学习方法就是一种思路。专家轨迹和行为轨迹的接近程度可以通过测量两个轨迹之间的最佳传输来计算。
6.2 方法
(1)BC 预训练
使用 BC 对专家演示的数据进行随机初始化策略的训练。
BC 对应求解公式中的最大似然问题,这里的专家轨迹 $T^e$ 指的是专家演示,训练后,它能够使 $\pi^{BC}$ 模仿与演示中想对应的动作,但是如果出现未见过的状态,那么很容易会导致推理失败。
(2)在线 IRL 微调
在 BC 训练的模型基础上,进行在线微调策略。由于本文操作没有明确的任务奖励,因此使用基于 OT 的轨迹匹配获得奖励。(本文使用了 n 步 DDPG 方法实现连续控制)
- 正则化微调:由于在线部署期间很容易因为错误累计导致分布偏移,本文通过基于引导 RL 和离线 RL 将 $\pi^{ROT}$ 与 BC 损失相结合来规范 $\pi^{ROT}$ 的训练,此处设置了一个 $\lambda(\pi)$ 自适应权重来控制两个损失项的贡献。
- 柔性 Q 滤波的自适应正则化:自适应权重调整 $\lambda(\pi)$,通过比较当前策略 $\pi^{ROT}$ 和与训练策略 $\pi^{BC}$ 在一段重放缓冲区采样的一批数据的性能表现来完成。
- 基于图像观测的考虑:对视觉观测进行数据增强,将图像输入 CNN 编码器,获得 OT 奖励的计算,减少 ROT 模仿过程中的非平稳性。
6.3 实验
本文的模型包括三个神经网络:encoder、actor、critic,三者均使用均方误差进行训练。
使用 n 步 DDPG 作为 RL 主干,actor 使用确定性策略梯度进行训练。critic 使用 clipped double Q-learning 进行训练,主要时为了减少高估问题,因此使用两个 Q 函数实现 critic 的学习。
 微信支付
微信支付 支付宝
支付宝