【论文笔记】Dex 演示引导强化学习与手术机器人任务自动化的高效探索
一、论文笔记
标题:Demonstration-Guided Reinforcement Learning with Efficient Exploration for Task Automation of Surgical Robot
标题:演示引导强化学习与手术机器人任务自动化的高效探索
作者团队:香港中文大学(刘云辉团队)
期刊会议:ICRA
时间:2023
代码:https://github.com/med-air/DEX
1.1 目标问题
虽然基于强化学习的方法为手术自动化提供了可能的方案,但是通常需要大量收集数据才能进行学习。因此本文目的是提高从演示中探索学习的效率,有效地利用专家演示数据。
具体而言,目前的问题如下:
- 使用强化学习,如果不给出演示数据而仅通过探索学习,需要收集大量的数据来解决任务;
- 使用演示数据的方法,例如赋予演示数据相对于机器人探索数据更高的优先级,效率仍然低下,设置额外奖励函数的方法不仅只能针对特定环境,且容易引起局部最优;
- 使用 actor-critic 框架,通过正则化 actor 损失来衡量机器人与专家之间的行为差异,但是这种方式效率较低(尤其在初期机器人与演示差距较大情况下),且没有考虑 critic 的正则化,容易导致高估问题。
本文贡献:
- 提出一种 actor-critic 框架,降低 critic 的高估问题,提高强化学习过程中类似专家的行动进行探索。
- 使用非参数引导传播,实现未观测状态的探索
- 在 SurRoL 手术机器人上实验验证,效果优秀,同时部署在 dVRK 上,同样表示出强大的潜力。
dVRK(da Vinci Research Kit,达芬奇手术机器人系统)
1.2 方法
DEX(Demonstration-guided EXploration),演示引导探索。
(0)问题定义
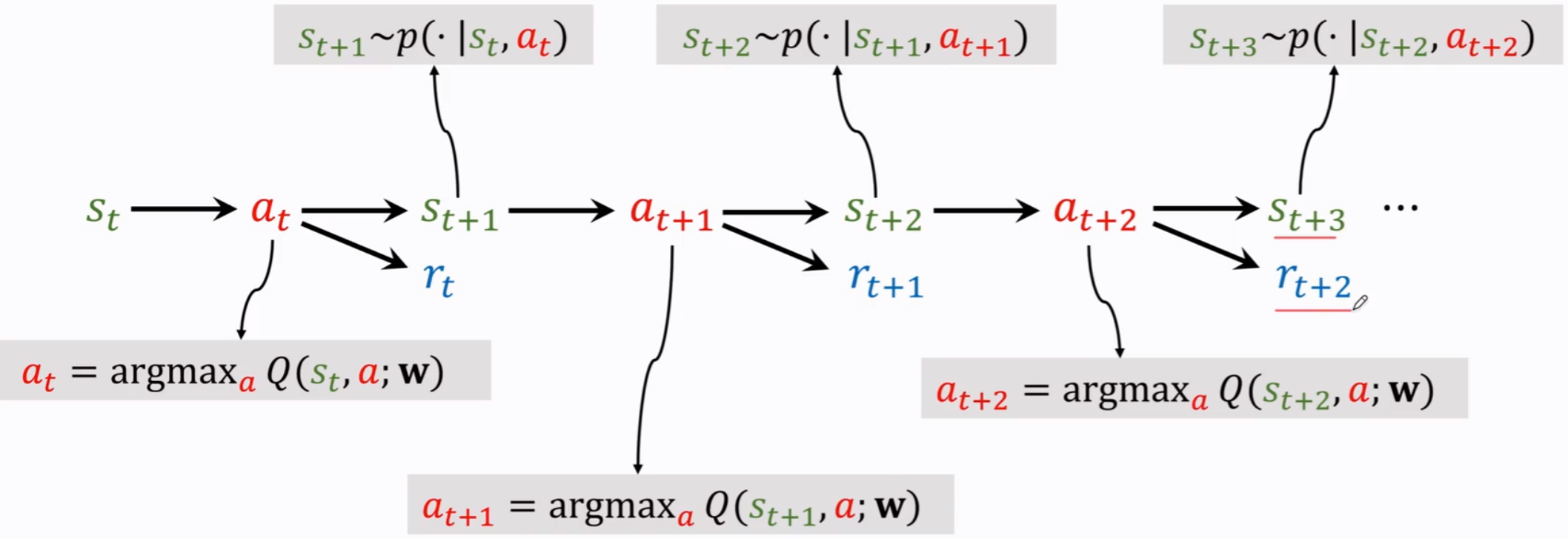
将手术机器人动作学习考虑为一个 off-policy 的智能体,在由马尔可夫决策过程构建的环境中进行交互。
off-policy,指智能体不使用当前的策略来决定行动,而是使用不同的策略来生成行为数据,从过去的经历中学到最优的行为决策方法。
在 $t$ 时刻,机器人根据当前状态 $s_t$ 以及确定性策略 $\pi$ 执行行动,环境用 $r_t=r(s_t,a_t)$ 奖励智能体,然后状态转移 $s_{t+1}$。
循环此过程,每次智能体将经验 $(s+t,a_t,r_t,s_{t+1})$ 存入重放缓冲区 $D_A$。
同时设置一个演示缓冲区 $D_E$,用于存放专家策略 $\pi$ 经验。
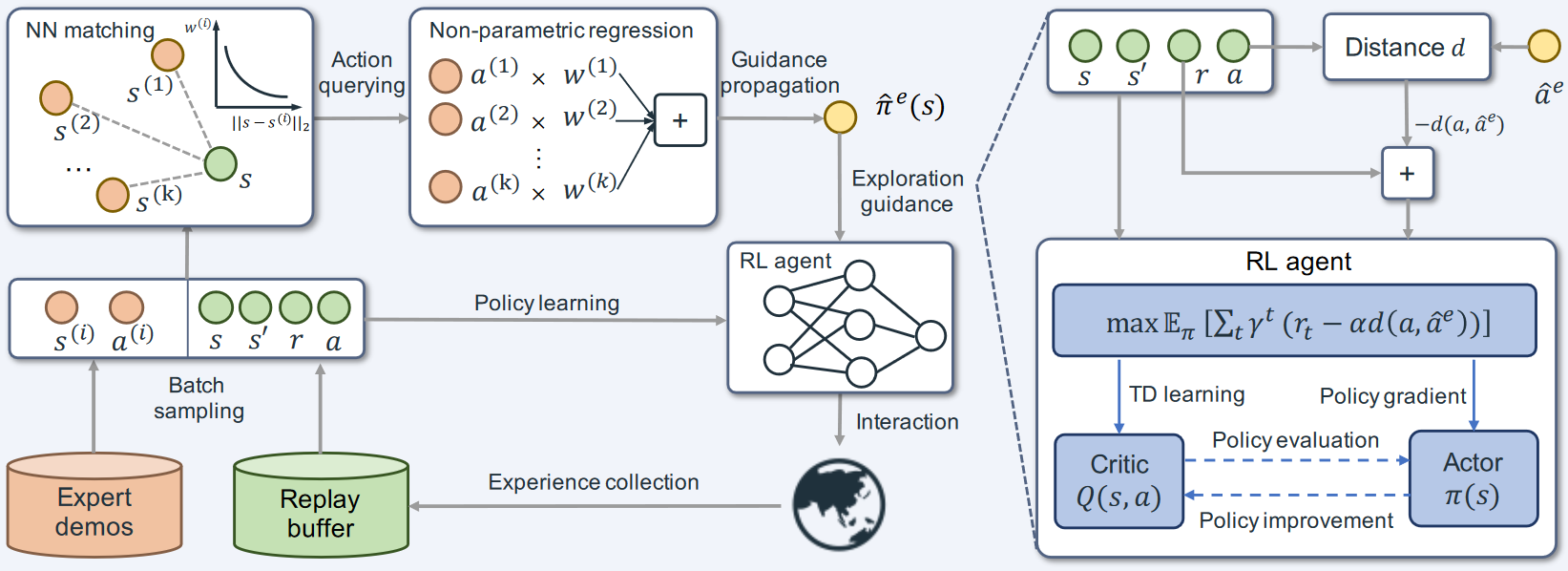
如图,该方法由两部分组成:
- 基于 actor-critic 的策略学习模块(右下角),用于从演示数据中指导探索;
- 基于最近邻匹配和局部加权回归的非参数模块(左上角),用于将与当前状态相差过大的演示传播到为当前状态。
(1)专家引导的 actor-critic 框架
现有的 actor-critic 方法通过最大化预期回报来学习最优策略,但是如果 Q 值估计不准确,会阻碍探索。本文通过利用智能体和专家策略之间的动作差距来增强环境奖励。
$$
\max_{\pi}\mathbb{E}{\pi}\left[\sum{t=0}^{\infty}\gamma^{t}(r_{t}-\alpha d(a_{t},a_{t}^{e}))\right],a_{t}^{e}:=\pi^{e}(s_{t}),
$$
其中 $\alpha$ 是探索系数,$d()$ 衡量智能体动作和专家动作之间的相似性距离度量。
基于此奖励,本文设计了正则化 Q 函数(critic),并最小化动作价值和状态价值的差距。
(2)有限演示情况下的引导的传播
智能体在初始学习阶段很容易探索演示未覆盖的区域,无法实现监督 actor 探索。
常规的解决思路有行为克隆,但是当状态相差较大时,策略与专家行动仍会有较大的不同。因此本文使用非参数回归模型,从有限的演示中将经验传播实现更稳定的引导。
首先从演示缓冲区采样一小批状态和动作,然后给定一个当前状态,在一小批状态中搜索,利用 k 近邻方法找到最接近的状态,然后使用指数和函数的局部加权回归方法近似专家策略。
$$
\hat{\pi}^e(s)=\frac{\sum_{i=1}^k\exp\left(-|s-s^{(i)}|2\right)\cdot a^{(i)}}{\sum{i=1}^k\exp\left(-|s-s^{(i)}|_2)\right)}.
$$
二、算法复现
2.1 环境配置
clone代码
1 | git clone --recursive https://github.com/med-air/DEX.git |
创建虚拟环境
1 | conda create -n dex python=3.8 |
安装依赖
1 | pip3 install -e SurRoL/ # install surrol environments |
在虚拟环境的gym/envs/__init__.py的第一行注册SurRoL任务
1 | directory: anaconda3/envs/dex/lib/python3.8/site-packages/gym/envs/__init__.py |
2.2 数据采集
1 | mkdir SurRoL/surrol/data/demo |
2.3 训练
1 | python3 train.py task=NeedlePick-v0 agent=dex use_wb=True |
作者提供的程序中也包括了其它强化学习与模仿学习算法,例如:
- DDPG:深度确定性策略梯度的强化学习
- DDPGBC:深度确定性策略梯度的强化学习+行为克隆
- SAC:最大熵无模型深度强化学习
- SQIL:正则化行为克隆的模仿学习
- COL:行为克隆与强化学习
- AWAC:离线强化学习
- AMP:对抗模仿学习
三、代码理解
3.1 基本定义
(1)机器人状态
通过以下函数获取机器人状态。
1 | # SurRoL.surrol.tasks.psm_env.PsmEnv._get_robot_state |
因此机器人的状态为一个数组:
1 | robot_state = [x, y, z, roll, pitch, yaw, gripper] |
(2)观测状态
观测状态通过以下方法进行获取:
1 | # SurRoL.surrol.tasks.psm_env.PsmEnv._get_obs |
可以看出观测状态是一个字典,包含三个键:observation, achieved_goal, desired_goal。
- observation: 由robot_state, object_pos.ravel(), object_rel_pos.ravel(), waypoint_pos.ravel(), waypoint_rot.ravel()组成,
| obs | 键值(三个都是一维数组) | 含义 |
|---|---|---|
| observation | [robot_x, robot_y, robot_z, robot_roll, robot_pitch, robot_yaw, gripper, | 机器人末端位姿和夹爪状态 |
| obj_x, obj_y, obj_z, | 目标物体位置 | |
| obj_rel_x, obj_rel_y, obj_rel_z, | 目标物体与当前机械臂相对位置 | |
| obj_link1_x, obj_link1_y, obj_link1_z | 目标物体的link1位置作为waypoint位置 | |
| obj_link1_roll, obj_link1_pitch, obj_link1_yaw] | 目标物体的link1姿态作为waypoint姿态 | |
| achieved_goal | [x, y, z] | waypoint作为实际位置,未设置link1则用目标物体位置作为实际位置,无物体则用机器人末端位置为实际位置 |
| desired_goal | [x, y, z] | 机器人末端的目标位置 |
(3)机器人动作
机器人动作通过以下方法进行执行:
1 | # SurRoL.surrol.tasks.psm_env.PsmEnv._set_action |
其中机器人动作是一个长度为5的数组
1 | action[5] = [delta_x, delta_y, delta_z, yaw/pitch, gripper] |
- 其中
delta_xyz代表机器人末端在xyz轴上的位移量; - yaw/pitch根据类变量ACTION_MODE定义使用哪种旋转;
- 夹爪为负数则关闭,如果为非负数则根据数值大小确定打开大小。
四、代码修改
4.1 环境补充
1 | pip install hydra-core colorlog termcolor opencv-python perlin_noise |
4.2 测试
- AWAC:离线强化学习
(1)DDPGBC:深度确定性策略梯度的强化学习+行为克隆
| DDPGBC | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 无法成功 | 无法成功 |
| Trajectory Reward | 无法成功 | |
(2)SAC:最大熵无模型深度强化学习
| SAC | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 平移物体到达位置,成功率高 | 平移物体到达位置,成功率高 |
| Trajectory Reward | 平移物体到达位置,成功率高 | |
(3)SQIL:正则化行为克隆的模仿学习
| SQIL | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 无法成功 | 无法成功 |
| Trajectory Reward | 无法成功 | |
(4)COL:行为克隆与强化学习
| CoL | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 无法成功 | 无法成功 |
| Trajectory Reward | 无法成功 | |
(5)AWAC:离线强化学习
| AWAC | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 平移物体到达位置,成功率低 | 平移物体到达位置,成功率高 |
| Trajectory Reward | 无法成功 | |
(6)AMP:对抗模仿学习
| AMP | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 平移物体到达位置,成功率高 | 平移物体到达位置,成功率高 |
| Trajectory Reward | 平移物体到达位置,成功率高 | |
(7)DEX:演示引导的强化学习
| DEX | Demo 1000 | Demo 10000 |
|---|---|---|
| Success Reward | 无法成功 | 无法成功 |
| Trajectory Reward | 无法成功 | |
 微信支付
微信支付 支付宝
支付宝